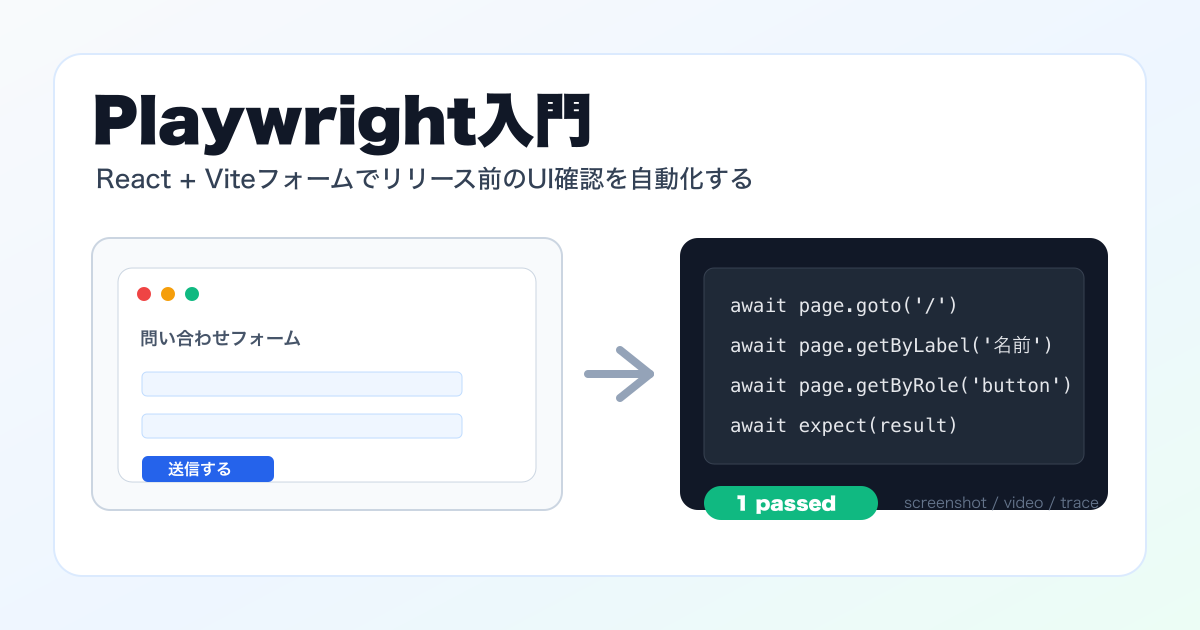
ナスオモリの沈み方を見比べるWebアプリを作りました
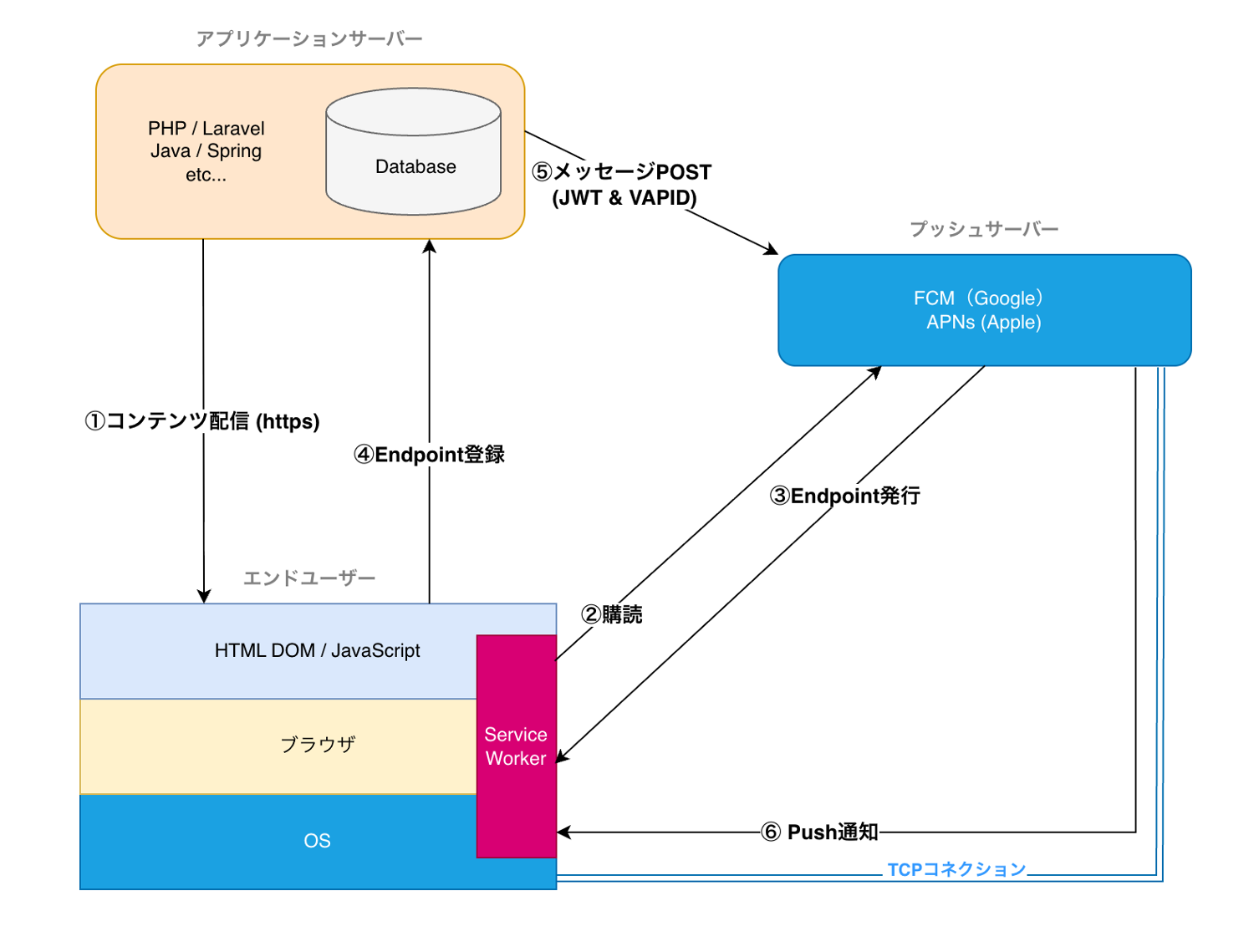
ナスオモリの重さや素材を変えると、底につくまでの時間はどれくらい変わるのでしょうか。 釣り場では、なんとなく「重い方が速い」「タングステンは小さいから沈みやすそう」と考えています。ただ、その差を数字や動きで見比べようとすると、頭の中だけでは整理しにくいです。 そこで、ナスオモリの沈み方を見比べるための小さなWebアプリを作りました。 ナスオモリ沈下シミュレーター 重さ・金属・水深で着底時間を比較 開く アプリ: ナスオモリ沈下シミュレーター 計算根拠: ナスオモリの沈み方をどう計算しているか この記事では、アプリでできることと、釣り場でどう使うとよさそうかをまとめます。 作った理由 最近、ゴロタ浜やサーフで底を探る釣りをすることが増えました。 底の石に当たる感触、根掛かりしにくさ、アタリの出方。こういうものは、シンカーの形や浮力でかなり変わります。フロートシンカーは根掛かりには強いですが、底からの情報は少なくなります。逆に普通のオモリは底の情報が出やすいものの、場所によっては根掛かりが怖いです。 その中で、ふと気になったのが「沈む時間」でした。 同じ1oz前後でも、鉛、タングステン、ブラス、鉄では体積が違います。重くすれば速く沈みますが、体積も大きくなって水の抵抗も増えます。仕掛けやラインまで含めると、さらに単純な話ではなくなります。 もちろん、実際の海では潮流、糸ふけ、エサ、仕掛けの姿勢で結果が変わります。ですから、このアプリは正解を出すためのものではありません。条件を変えたときに、沈み方の傾向を見比べるための道具として作りました。 このアプリでできること アプリでは、4つのナスオモリを同時に並べて沈められます。 それぞれのオモリについて、素材と重さを変えられます。素材は鉛、タングステン、ブラス、鉄です。重さは1gから120gまでの範囲で指定できます。 鉛 タングステン ブラス 鉄 水の条件も変えられます。 水深:1mから100m 水質:真水、海水 水の抵抗:0.10から4.00 画面には、代表オモリの着底時間、終端速度、水の密度、実際に沈む距離が表示されます。アニメーションを止めたり、タイムラインを動かしたりしながら、同じ条件で沈み方の差を見られるようにしました。 たとえば、鉛の10g、14g、21g、28gを並べれば、一般的な号数違いの感覚へ近づきます。素材だけを変えれば、同じ30gでもタングステンの方が小さく、ブラスや鉄の方が大きくなることも見えやすいです。 まずは基本条件で見比べる 最初は、初期値のまま眺めるのが分かりやすいです。 初期状態では、海水、水深5m、水の抵抗2.00で、鉛の10g、14g、21g、28gを並べています。アプリ上の沈下距離は、オモリの見た目サイズを考慮して、水深より少し短くなります。 オモリ 素材 沈下距離の目安 終端速度の目安 着底時間の目安 10g 鉛 4.37m 0.88m/s 5.0秒 14g 鉛 4.30m 0.94m/s 4.7秒 21g 鉛 4.19m 1.00m/s 4.3秒 28g 鉛 4.11m 1.05m/s 4.0秒 このくらいの浅い水深では、違いは数秒単位ではなく小数秒として出ます。釣りをしている最中に正確に感じ分けるのは難しいかもしれませんが、「重さを上げるほど速くなる。ただし倍の重さでも半分の時間にはならない」という傾向は見えます。 もう少し差を見たいときは、水深を20mや50mへ上げると分かりやすいです。水深が深くなるほど、終端速度に近い状態で進む時間が長くなり、素材や抵抗の違いが表に出やすくなります。 同じ30g、水深20m、海水、水の抵抗2.00で素材だけを変えると、おおよそ次のようになります。 素材 終端速度の目安 着底時間の目安 鉛 1.06m/s 18.1秒 タングステン 1.29m/s 14.9秒 ブラス 0.95m/s 20.2秒 鉄 0.92m/s 20.8秒 同じ重さなら、密度が高いタングステンは体積が小さくなり、水の抵抗を受ける面積も小さくなります。そのため、このモデルでは鉛より速く沈みます。ブラスや鉄は鉛より体積が大きくなり、少し遅く沈みます。 ...