文章AとBの類似率を数値化するJaccard係数をシェル・sqlite・mecabで実現してみた
はじめに
このブログの記事Aと記事Bがどれだけ類似しているかを検出して、関連記事を自動化したいと思った。そこで簡単に思いつく方法は、それぞれの記事のキーワードを抽出し、お互いどれだけ共通のキーワードを持っているか調べれば良さそう。
そこでJaccard係数という手法を見つけた。
Jaccard係数とは
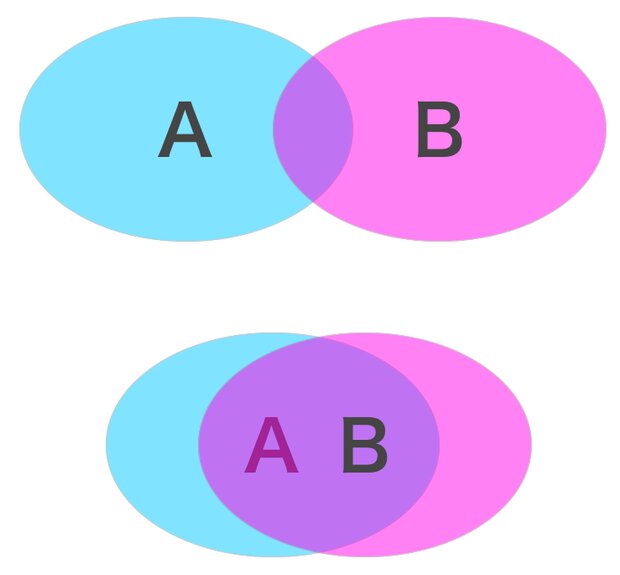
Jaccard係数は、2つの集合 ( A ) と ( B ) の類似度を測る数学的なアプローチ。
\[ J(A,B)=\frac{|A\cap B|}{|A\cup B|} \]
記事Aと記事Bのキーワードに当てはめて集合を考えると、
- 重複を取り除いた記事Aと記事Bのキーワードの合計が分母
- 重複する部分のキーワードだけを抽出したのが分子
となる。そしてこの割り算の結果をJaccard係数とし、 係数が大きいほど類似度が高いことを意味する。
Jaccard係数はsqliteで簡単に計算できる
次は、実際にこのブログサイトで関連記事を作成するために使っているSQLである。 全ての記事に対してJaccard係数を計算し、係数が0.1以上のものを関連記事として抽出する処理をさせている。
WITH
target_words AS (
SELECT word
FROM keywords
WHERE filename = '__FILENAME__'
),
intersections AS (
SELECT k.filename, COUNT(*) AS intersect_count
FROM keywords k
JOIN target_words t ON k.word = t.word
WHERE k.filename != '__FILENAME__'
GROUP BY k.filename
),
unions AS (
SELECT k.filename,
COUNT(DISTINCT k.word)
+ (SELECT COUNT(DISTINCT word) FROM target_words)
- COUNT(DISTINCT CASE WHEN k.word IN (SELECT word FROM target_words) THEN k.word END) AS union_count
FROM keywords k
WHERE k.filename != '__FILENAME__'
GROUP BY k.filename
)
SELECT
i.filename,
CAST(i.intersect_count AS REAL) / u.union_count AS jaccard
FROM intersections i
JOIN unions u ON i.filename = u.filename
WHERE CAST(i.intersect_count AS REAL) / u.union_count >= 0.1
ORDER BY jaccard DESC;
複雑に入り組んでいて読みにくいが、Jaccard係数を計算するために共通部分の要素を求めるintersectionsと、キーワードの和集合を求めるunionsがポイントである。
mecabで記事のキーワードを抽出
あらかじめmecabを使って記事ごとに形態素解析を走らせて、一般名詞でキーワードを抽出させている。
echo "$content" | mecab -Ochasen \
| awk '$4 ~ /^名詞-一般/ { print $1 }' \
| gawk 'length($0) > 1' \
| tr '[:upper:]' '[:lower:]' \
| grep -vFf "$IGNORE_FILE" \
| sort | uniq -c | sort -nr \
| head -n 10 \
| awk '{print $2}' \
| paste -sd "\n" -これらの結果を、filenameに対応付けてkeywordsテーブルに格納されている。 ただしここでのポイントは、keywordsテーブルではfilenameに対してkeywordがN対Nで格納しているということである。

このことにより、Jaccard係数を計算するSQL文を簡潔に書くことができ、DBの性能をフル活用して軽量で高速な計算が可能となる。
Jaccard係数を使った考えられる用途
Jaccard係数は関連記事の計算以外にも色々な分野で使われてそうである。
- 文章記事であれば重複コンテンツの検出
- 検索エンジンでは、検索クエリとウェブページの内容との類似度評価
- レコメンデーション、つまりユーザーの嗜好や過去の選択を集合として扱いう「おすすめ表示」などのコンテンツ
- 特徴量の集合として表現されるデータ間の類似度評価であれば、画像の特徴抽出や遺伝子データの解析などいくらでも応用可能
AI革命以降の時代においては、Jaccard係数はAI未然の古典的な機能と呼ばれる日も近いのかもしれない。しかし、シンプルなロジックであるからゆえに、幅広い分野で永劫未来において有効であるとも思うのである。