【tesseractでOCR】PDFから文字の抽出→文字データが埋め込まれたPDFを作成【自炊への道】
今回は自炊でスキャンしたPDFファイルを、シェルコマンドでOCR処理するちょっとマニアックな方法をご紹介いたします。
文字データが埋め込まれたPDFを作成するまでの手順
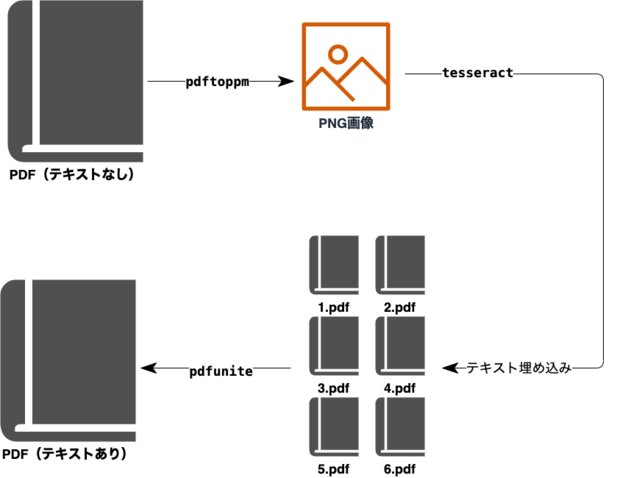
残念ながらPDFから直接文字データを埋め込むようなコマンドが見つかりませんでした。ですので下図のような流れで複数のシェルコマンドを駆使しながら、文字データが埋め込まれたPDFを作成していきます。
tesseract(OCR)
はじめに、画像データから文字を認識してPDF化するtesseract(OCR)を使ってみましょう。
tesseractのインストール
macOSの場合は、brewでインストールできます。デフォルトでは英語のみしか認識できませんので、日本語にも対応するように
tesseract-lang を合わせてインストールします。
$ brew install tesseract tesseract-langこのようにインストールできました。
$ tesseract -v
tesseract 5.2.0
leptonica-1.82.0
libgif 5.2.1 : libjpeg 9e : libpng 1.6.37 : libtiff 4.4.0 : zlib 1.2.11 : libwebp 1.2.2 : libopenjp2 2.5.0
Found AVX2
Found AVX
Found FMA
Found SSE4.1
Found libarchive 3.6.1 zlib/1.2.11 liblzma/5.2.5 bz2lib/1.0.8 liblz4/1.9.3 libzstd/1.5.2
Found libcurl/7.79.1 SecureTransport (LibreSSL/3.3.6) zlib/1.2.11 nghttp2/1.45.1日本語が使えるか確認しましょう。
$ ls /usr/local/share/tessdata/ | grep jpn
jpn.traineddata
jpn_vert.traineddataさっそく、文字が含まれているこちらの画像をOCRしてみましょう。

日本語の文字でしたら、次のようにして tesseract
を実行します。
$ tesseract kokoro-captured.png out -l jpnout.txt
が出力され、画像内の文字をテキストとして抽出できました。

テキストが埋め込まれたPDFにする
テキストが埋め込まれたPDFにするには、次のように実行します。
$ tesseract kokoro-captured.png out -l eng+jpn pdfこれで、画像の上に透明なテキストが追加されているはずです。PDF内の文字が検索できるようになりましたね!

つかわない言語を削除
ところで最初に brew でインストールした
tesseract-lang
には世界中の言語が含まれているため、無駄にディスク容量を占領します。ですので使わない言語は削除してしまいましょう。
$ du -sh /usr/local/Cellar/tesseract-lang/4.1.0/share/tessdata
654M /usr/local/Cellar/tesseract-lang/4.1.0/share/tessdata英語(eng)と日本語(jpn)しか使いませんので、それ以外は削除しちゃいました。
$ cd /usr/local/Cellar/tesseract-lang/4.1.0/share/tessdata
$ mv jpn.traineddata jpn_vert.traineddata ~/Desktop
$ mv * ~/.Trash
$ mv /Users/mopipico/Desktop/jpn.traineddata /Users/mopipico/Desktop/jpn_vert.traineddata .英語(eng)は別のところに保存されているようなので、jpn.traineddata
と jpn_vert.traineddata だけ残せばOKです。
tesseract
でテキスト抽出のテストをして、問題なければゴミ箱を空にしてしまいましょう。
$ tesseract hoge.png hoge -l eng+jpn pdf自炊したPDFをテキスト埋め込みPDFにする
ここからは、自炊したPDFをテキスト埋め込みPDFにしていく方法を解説します。
popplerのインストール
PDFをPNGファイルに変換する pdftoppm
と、複数のPDFファイルを一つにまとめる pdfunite
が必要になります。これらを使えるようにするため brew で
poppler をインストールしましょう。
$ brew install popplerPDFから各ページをPNG画像へ変換する(pdftoppm)
pdftoppmコマンドを用いて、PDFをPNG形式の画像に変換します。
$ mkdir tmp
$ pdftoppm -png -r 200 -gray 自炊ファイル.pdf tmp/pageここではグレースケールにしてますが、カラーで表示したい場合は-grayを削除してください。
pdftoppm の主なオプションです。
| オプション | 意味 |
|---|---|
| -scale-to | 画像サイズを指定したピクセル数に縮小する |
| -r 数値 | DPIの値(デフォルトは150) |
| -gray | グレースケールで出力する(PGM形式) |
| -png | PNG形式で出力する |
| -jpeg | JPEG形式で出力する |
-r
オプション、つまりDPIの値は元のPDFファイルによって調節する必要があります。高くしすぎると処理に時間がかかり、ファイルサイズも大きくなってしまいますのでご注意ください。
tesseractでOCR処理
PDFファイルを一枚一枚の画像に出力したところで、それらに
tesseract
でOCR処理を施してPDF化していきます。つぎのようにパイプで連携させて処理させます。
$ find "./tmp" -type f -name "*.png" | sed 's/\.png$//' | xargs -P8 -n1 -I% tesseract %.png % -l eng+jpn pdfxargs の -P
オプションは、同時実行数の最大値、-n
オプションは、xargs に渡す引数の最大値、-I
オプションは、標準入力より渡されたデータを、
任意の引数に展開することが可能です。
これでテキストが埋め込まれたPDFファイルが作成できました。ただし、ページ毎にファイルがバラバラですので、pdfunite
を使って一つのPDFにします。
pdfuniteで複数のPDFファイルを連結して、ひとつのPDFにまとめる
次のようにして、複数のPDFファイルをひとつのPDFにまとめます。
$ pdfunite tmp/*.pdf output.pdfさて、tmp
ディレクトリ内の画像やPDFは必要ありませんので削除してしまいましょう。
$ mv tmp ~/.Trashこれでめでたく、自炊したPDFファイルにテキスト文字を埋め込むことができました。完成したpdfは、2倍くらいのサイズになりました。
$ du -sh *
15M 自炊ファイル.pdf
29M output.pdf一括で実行できるシェルスクリプト
ここまでの流れを一括で処理できるシェルスクリプトを作ってみました。
#!/bin/bash
PDF_PATH=$1
FILE_NAME=`basename $PDF_PATH .pdf`
TMP_DIR=tmp_$FILE_NAME
TRASH_DIR=~/.Trash
mkdir $TMP_DIR
pdftoppm -png -gray -scale-to 1000 $PDF_PATH $TMP_DIR/page
find "./$TMP_DIR" -type f -name "*.png" | sed 's/\.png$//' | xargs -P8 -n1 -I% tesseract %.png % -l eng+jpn pdf
mv $FILE_NAME.pdf ~$FILE_NAME.pdf
pdfunite $TMP_DIR/*.pdf $FILE_NAME.pdf
mv $TMP_DIR $TRASH_DIRこのようにして実行します。
./ocr.sh 自炊ファイル.pdf元データは ~自炊ファイル.pdf
としてバックアップされます。
【おまけ】自炊スキャンでつかえる神アプリ「vFlat」が超便利!
さいごに、できるだけお金をかけずに自炊ができるスキャナーアプリをご紹介します。App StoreやGoogle Playで「vFlat」で探してみてください。 このアプリ、無料ですが本当にすごいです!次のようなことができちゃいます。
- 本の歪みを直してくれる
- 指が映っても削除してくれる
- 自動でシャッターを押してくれる
- 日本語もOCR処理でテキストを埋め込める

もちろん裁断してスキャンする方法に比べれば歪みは残りますが、比較的キレイに自炊してくれます。他のスキャナアプリで満足できなかった方は、vFlatをぜひお試しください。
ただし、一日つかえるOCRのページ数が限られてます。そのため、OCR処理はこの記事でご紹介した
tesseract を使うと良いです。
▼ こんな感じで、サクッと自炊できちゃいます。