Excelなどの表データをゴリゴリ加工する【Python x Pandas】

この記事では、Pythonを使ってデータ解析を簡単に行うことができるpandasの使い方を解説していきます。
Pandasとは、表データをPythonで簡単に扱えるようにするライブラリです。表データをDataFrameというオブジェクトへ変換し、並べ替えたり、特定の行や列を取り出したり、追加削除などの加工を簡単にプログラミングできます。 https://pandas.pydata.org/
本記事では、Pandasで読み込んだExcelデータから必要な情報だけ抽出し、並べ替えたり、グラフ表示させたりしていきます。いわゆるスクレイピングと呼ばれる作業のひとつになります。
Pandasの準備
プログラミング作業に入る前に、Pandasの準備などを行なっていきます。なお本記事では、macOS上のPython 3.9.4で作業を行ないました。
Pandasのインストール
はじめに、必要なライブラリのインストールを行いましょう。pandas以外にも、グラフ表示を行うためmatplotと、その日本語文字化け対策にjapanize_matplotlib、また、Excelファイルを読み込むxlrdと書き込むxlwtもあわせてインストールします。pip3コマンドを使って、次のようにインストールしてください。
$ pip3 install pandas
$ pip3 install matplotlib
$ pip3 install japanize_matplotlib
$ pip3 install japanize_matplotlib
$ pip3 install xlrd xlwt表データの名称
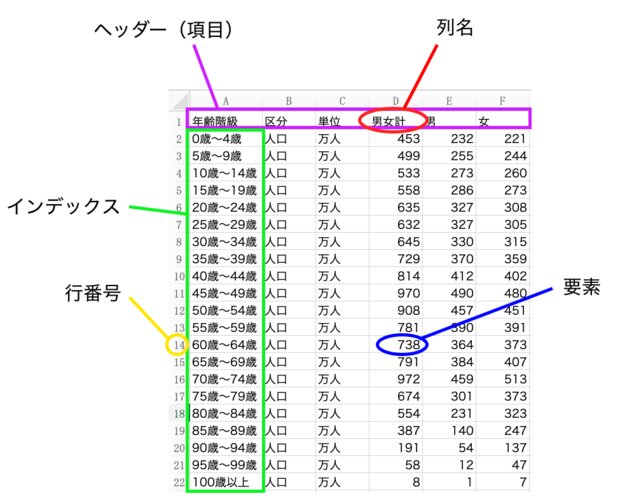
表データの名称を確認しておきましょう。縦方向を列、横方向を行と呼びますので、行番号、列名、ヘッダー、要素はそれぞれ次の図のとおりです。
Pandasの使い方
それではpandasの使い方を説明していきます。
ライブラリをインポートする
PythonプログラムでPandasを使うときはimport pandas as pdのようにしてpdの名前で使えるようにします。matplotも使用しますので、次のように必要に応じてライブラリをインポートしてください。
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib表データを読み込む(Excel、CSV)
PandasではExcelやCSVなどの表データを簡単に読み込むことができます。Pandasで読み込んだ表データはDataFrameというオブジェクトへ変換されます。これによって、表データをPythonで簡単に扱うことができます。
なおこの記事ではデータフレームの変数名をdfとします。
Excelファイルの読み込みの読み込みは次のように行います。sheet_nameでシートを指定できます。
df = pd.read_excel('ファイル名.xlsx', sheet_name='シート名')CSVファイルの読み込みの読み込みは次のように行います。
df = pd.read_csv('ファイル名.csv') エンコードを指定して文字化け対処
CSVファイルがUTF-8でない場合、ファイルの読み込み時に次のようなエラーになります。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x83 in position 0: invalid start byteこれを回避するには次のようにエンコードを指定してください。
df = pd.read_csv('ファイル名.csv', encoding="SHIFT-JIS") データ情報を表示する
読み込んだデータの情報を、次のようにして確認できます。
print(df) # データの中身
print(len(df)) # データの件数
print(df.columns.values) # ヘッダー(項目名一覧)
print(df.index.values) # インデックス一覧行番号がインデックスとして登録されます。
列データや行データを抽出する
特定の列データを抽出したい場合、df['列名']で列データを抽出できます。また、df[['列名1', '列名2']]のように複数の指定も可能です。
column = df['列名']行データを表示する場合は、df.loc[行番号]を使います。df.loc[[行番号1, 行番号2]]のように複数の指定も可能です。
row = df[行番号]また、行番号と列名を指定すれば要素を取り出すことができます。
value = df.loc[行番号]['列名']条件をつけてデータを抽出する
条件をつけてデータを抽出できます。
df = df[df['列名'] >= 70]複数条件の場合は、次のように書きます。
df = df[(df['列名'] >= 0) & (df['列名'] < 70)]条件演算子は、andは&、orは|、notは~を使います。
インデックスを指定して読み込む
次のように、index_colでインデックスとなる列、headerでヘッダーとなる行を指定して読み込むことができます。
df = pd.read_excel('ファイル名.xlsx', index_col=インデックス列番号, header=ヘッダー行番号)表データを読み込む際にindex_colでインデックスを指定すると、インデックス名で行を選択できます。
df.loc['インデックス名']['列名']ただし、index_colを指定した場合、行番号では指定できなくなります。
後からインデックスの列を変更を行うには、次のようにして再定義できます。
df = df.set_index('列名')データを追加・変更する
行データの追加と書き換えは次の通り行います。
df.loc[行番号 or 'インデックス'] = [データ1, データ2, ... , データN]ただし、表データ読み込み時にindex_colを使用しているかどうかで、インデックスの指定が異なりますので注意してください。
また、すでに行にデータが存在する場合は、上書きされて書き換えられます。
また、表データと同じ項目数を代入しないとエラーになります。
ValueError: cannot set a row with mismatched columns一方、列データの追加と書き換えは次の通り行います。
df['列名'] = [データ1, データ2, ... , データN]行を追加する
append関数を使うと簡単に行を追加できます。
df = pd.DataFrame(index=[], columns=['date', 'description'])
df = df.append({'date': '20210921', 'description': 'hogehoge'}, ignore_index=True)
df = df.append({'date': '20210925', 'description': 'fugafuga'}, ignore_index=True)
return df特定の要素を書き換える
特定の要素を指定して新しいデータで書き換える場合は注意が必要です。次のようにデータを更新しようとするとエラーになります。
df.loc[行番号]['列名'] = 新しいデータ次のようなSettingWithCopyWarningというエラーが吐き出されました。
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame詳しい原因はわかりませんが、次ように指定すればエラーなく書き換えることができました。
df.loc[行番号, ['列名']] = 新しいデータ列データや行データを削除する
列データの削除は、drop関数で列名とaxis=1を指定します。
df = df.drop('列名', axis=1)行データの削除は、axis=0を指定します。
df = df.drop(行番号 or 'インデックス', axis=0)nanデータを取り除く
表データにnanデータが入っていると都合が悪い場合があります。次のプログラムは、特定の列にnanデータが入っていたら、その行を取り除くことができます。
df = df[df['列名'].notnull()]データを並べ替える
特定の列を基準にデータを昇順にソートします。
df = df.sort_values('列名')特定の列を基準にデータを降順にソートします。
df = df.sort_values('列名', ascending=False)データを集計する
次のように、列名を指定してデータを集計します。
df['列名'].max()
df['列名'].min()
df['列名'].mean()
df['列名'].median()
df['列名'].sum()ちなみに、meanは平均値で、medianは中央値となります。中央値とは、データを大きさ順に並べた時の真ん中に位置する値のことです。
中央値は、 メディアンフィルタ としてノイズが多いデータから正しい値を抽出する時に活躍します。
行と列を入れ替える
行と列を入れ替えるには.Tを付与します。
df.Tリスト型や辞書型に変換する
データフレームをリスト型の配列に変換します。
list = df.values.tolist()データフレームを辞書型の配列に変換します。
dict = df.to_dict()データフレームをファイルに書き出す(Excel、CSV)
データフレームをExcelファイルに書き出します。
df.to_excel("ファイル名.csv", sheet_name='シート名')データフレームをCSVファイルに書き出します。
df.to_csv("ファイル名.csv")インデックスやヘッダーを削除して保存するには、次のように指定します。
df.to_csv("ファイル名.csv", index=False, header=False)オープンデータを読み込んでみよう
ここまでで、一通りのpandasの使い方がわかりました。ここではオープンデータを使って実際にpandasで表データを読み込み、matplotでグラフ表示させます。
オープンデータとは
オープンデータとは、利用規約を守れば、誰でも自由に入手して利用することができるデータのことです。主に、政府や自治体、教育機関、企業などが公開してます。 たとえば「e-Stat」の 利用規約 を読みますと、「CC BY」ライセンスで公開されていることが確認できます。「CC BY」では著作者情報を記載してリンクを貼れば、自由に利用できるといった内容になります。 オープンデータのサイトには次のようなものがあります。
オープンデータのサイト一覧
https://www.e-stat.go.jp/ https://dashboard.e-stat.go.jp/kids/ https://data.city.sabae.lg.jp/ https://www.data.jma.go.jp/gmd/risk/obsdl/ https://www.post.japanpost.jp/zipcode/download.html https://www.data.go.jp/ https://gs.statcounter.com/
2021年8月国内の年齢、男女別人口のデータ抽出
ここでは「e-Stat」のオープンデータから、次のデータを利用させてもらいました。
年齢(5歳階級)、男女別人口(2021年3月平成27年国勢調査を基準とする推計値、2021年8月概算値)
リンク先からExcelファイルをダウンロードし、次のようにデータを抽出してみました。
import pandas as pd
df = pd.read_excel('05k2-3.xlsx', header=3)
df = df.drop(['時間軸コード', '区分', '単位'], axis=1) # 必要のない列の削除
df = df[df['年齢階級'].notnull()] # nanデータのセルを取り除く
df = df[(df['人口区分'] == '総人口') & (df['時点'] == '2021年8月1日現在(概算値)')] # 総数行の削除
df = df.drop(['人口区分', '時点'], axis=1) # 必要のない列をふたたび削除
df = df.drop(range(22, 32, 1), axis=0)
df = df.drop(0, axis=0)これで、次のような人口データを抽出できました。
| 年齢階級 | 男女計 | 男 | 女 |
|---|---|---|---|
| 0歳~4歳 | 453 | 232 | 221 |
| 5歳~9歳 | 499 | 255 | 244 |
| 10歳~14歳 | 533 | 273 | 260 |
| 15歳~19歳 | 558 | 286 | 273 |
| 20歳~24歳 | 635 | 327 | 308 |
| 25歳~29歳 | 632 | 327 | 305 |
| 30歳~34歳 | 645 | 330 | 315 |
| 35歳~39歳 | 729 | 370 | 359 |
| 40歳~44歳 | 814 | 412 | 402 |
| 45歳~49歳 | 970 | 490 | 480 |
| 50歳~54歳 | 908 | 457 | 451 |
| 55歳~59歳 | 781 | 390 | 391 |
| 60歳~64歳 | 738 | 364 | 373 |
| 65歳~69歳 | 791 | 384 | 407 |
| 70歳~74歳 | 972 | 459 | 513 |
| 75歳~79歳 | 674 | 301 | 373 |
| 80歳~84歳 | 554 | 231 | 323 |
| 85歳~89歳 | 387 | 140 | 247 |
| 90歳~94歳 | 191 | 54 | 137 |
| 95歳~99歳 | 58 | 12 | 47 |
| 100歳以上 | 8 | 1 | 7 |
人口データの集計
先ほどの人口データから、もっとも多い年齢階級を調べて表示させてみました。
...
mf_max = df['男女計'].max()
m_max = df['男'].max()
f_max = df['女'].max()
df_mf_max = df[df['男女計'] == mf_max]
df_m_max = df[df['男'] == m_max]
df_f_max = df[df['女'] == f_max]
print('男女計でもっとも多い年齢階級: {}, {}万人'.format(df_mf_max['年齢階級'].values[0], int(mf_max)))
print('男計でもっとも多い年齢階級: {}, {}万人'.format(df_m_max['年齢階級'].values[0], int(m_max)))
print('女計でもっとも多い年齢階級: {}, {}万人'.format(df_f_max['年齢階級'].values[0], int(f_max)))次のような結果です。
男女計でもっとも多い年齢階級: 70歳~74歳, 972万人
男計でもっとも多い年齢階級: 45歳~49歳, 490万人
女計でもっとも多い年齢階級: 70歳~74歳, 513万人グラフ表示
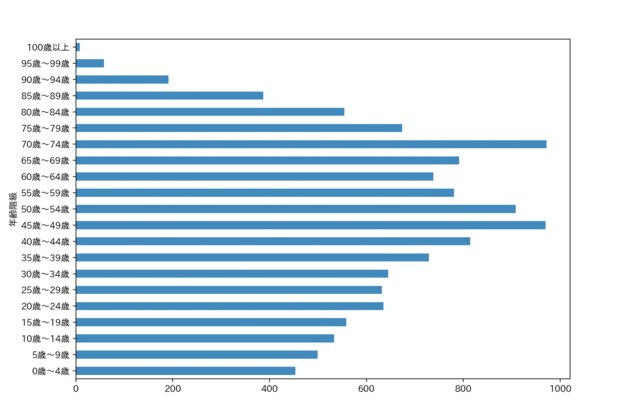
最後にmatplotでグラフ表示してみましょう。pandasのデータフレームは、df.plotという形でそのままグラフ表示ができます。
...
import matplotlib.pyplot as plt
import japanize_matplotlib
...
df = df.set_index('年齢階級') # インデックスの再定義
df[['男', '女']].plot.bar() # 棒グラフ
plt.show()
df['男女計'].T.plot.barh() # 行と列を総入れ替えして横棒グラフ
plt.show()次のようにグラフ表示ができました。 
関連記事
- Raspberry PiでSPI通信できるようにする設定【ADコンバータMAX1118】
- ESP32とMH-Z19CセンサでCO2濃度の測定
- iOSアプリ開発でSQLiteを使う FMDB
- 【tesseractでOCR】PDFから文字の抽出→文字データが埋め込まれたPDFを作成【自炊への道】
- ls・tree・sort・uniq コマンドの使い方