シェルコマンド・チートシート
grep
キーワードにマッチした行を表示
cat access.log | grep openai逆に除外したい場合、つまりキーワードにマッチしない行を表示するには
-v オプションをつけます。
cat access.log | grep -v openaiキーワードを含むファイルを検索
個人的にはとてもよく使う表現です。
grep -lr {キーワード} {起点ディレクトリ}実際に使うには grep -lr 'Flutter' . こんな感じです。
| オプション | 意味 |
|---|---|
| -n (–line-number) | 検索結果に行番号を表示 |
| -l (–files-with-matches) | 検索結果にファイル名のみを表示 |
| -r (–recursive) | ディレクトリ下のファイルを再帰的に読み取る |
さらに、拡張子を指定して対象ファイルを見つけることもできます。
grep -lr 'Flutter' . --include='*.md'マッチした行から前後数行も表示する
grep
で一致した行から前後数行を表示させることができます。-A
オプション(After)または -B
オプション(Before)で可能です。
cat some.log | grep "Error" -A 5 -B 1ls
基本オプション
| Option | 説明 |
|---|---|
-a |
隠しファイルを含めた表示 |
-l |
詳細情報を表示 |
-h |
ファイルサイズを人が読みやすい形(KB、MB)で表示 |
-r |
ファイルを逆順に表示 |
-t |
ファイルを変更時間でソートして表示 |
-S |
ファイルサイズでソートして表示 |
-G |
ファイルの種類で色分け表示 |
よく使うオプション例
| コマンド | 説明 |
|---|---|
ls -ltr |
変更時間順にソートしてファイル表示 |
ls -lhaSr |
ファイルサイズの大きい順に表示 |
ls -ld .* |
ドットファイルのみ表示する |
他のコマンドと組み合わせる
ls & grep
ls
コマンドは、他のコマンドと組み合わせて使用することで、さらに強力な操作が可能になります。以下は、ls
コマンドを他のコマンドと組み合わせた便利な例です。
ファイルやディレクトリのリストから特定のパターンにマッチするものだけを抽出したい場合、ls
コマンドの出力を grep コマンドにパイプで渡します。
ls -l | grep '^d'このコマンドは、現在のディレクトリ内のすべてのディレクトリ(-l
オプションで詳細表示されたリストの中で、行の先頭が d
で始まるもの)をリストアップします。
ファイルのみ表示させる場合は、次のようにします。
ls -l | grep '^-'ls & sort
ファイルのリストを特定の基準でソートしたい場合は、ls
コマンドの出力を sort コマンドにパイプで渡します。
ls -l | sort -k 5 -nこのコマンドは、ファイルサイズ(第5フィールド)に基づいて、ファイルのリストを数値的にソートします。
ls & wc
ディレクトリ内のファイルやサブディレクトリの総数を知りたい場合は、ls
コマンドの出力を wc
コマンドにパイプで渡して、行数をカウントします。
ls -1 | wc -lこのコマンドは、現在のディレクトリ内のファイルとサブディレクトリの総数を表示します。
ls & (head or tail)
ディレクトリ内のファイルリストの先頭や末尾の数ファイルだけを表示したい場合に便利です。
- 最初の5ファイルを表示:
ls -l | head -n 5- 最後の5ファイルを表示:
ls -l | tail -n 5ls & xargs
特定のファイルに対してバッチ操作を行いたい場合に、ls と
xargs を組み合わせます。
.txtファイルをすべて削除:
ls *.txt | xargs trashこれらの例は、ls
コマンドをより強力に使うための一部です。これらのコマンドを組み合わせることで、さまざまなタスクを効率的に実行することができます。この例では安全のためtrashを使っています。削除操作でrm
コマンドを行う場合は、操作の影響をよく理解してから実行してください。
tree
tree
コマンドで、現在のディレクトリ配下をツリー表示してくれます。
treeのインストール
brew install tree$ tree
.
├── composer.json
├── composer.lock
└── vendor
├── autoload.php
├── composer
│ ├── ClassLoader.php
│ ├── InstalledVersions.php
│ ├── LICENSE
│ ├── autoload_classmap.php
│ ├── autoload_files.php
│ ├── autoload_namespaces.php
│ ├── autoload_psr4.php
│ ├── autoload_real.php
│ ├── autoload_static.php
│ ├── installed.json
│ ├── installed.php
│ └── platform_check.php
├── guzzlehttp
│ ├── guzzle
...ただし、ディテクトり構造が大規模な場合はすべて表示されるため、オプションでフィルターをかけると便利です。
treeでよく使うオプションまとめ
| オプション | 意味 | コマンド例 |
|---|---|---|
| -d | ディレクトリのみ表示 | $ tree -d |
| -L level | 階層の深さを指定 | $ tree -L 2 |
| -I pattern | パターンにマッチするものを除外 | $ tree -I 'build\|src' |
| –gitignore | .gitignore でフィルタリング | $ tree --gitignore |
gitで管理している大規模プロジェクトなどでは、--gitignoreを使うとすごく便利です。もちろん
.gitignore が存在することが前提です。
$ tree --gitignoreとくにbuildディレクトリなど弾いてくれると、ツリー構造がとても見やすくなります。
sort
sortコマンドは、テキストファイルの内容を行単位で並び替えるために使用されます。標準入力からのデータや、指定したファイルの内容をソートすることができます。ここでは、sortコマンドの主なオプションと使用例を紹介します。
| 内容 | 実行コマンド |
|---|---|
| ファイル内容のソート | sort ファイル名 |
| 複数ファイルの内容を結合してソート | sort ファイル名1 ファイル名2 |
| オプション | 説明 |
|---|---|
-n |
数値としてソートします。デフォルトでは文字列としてソートされます。 |
-r |
逆順でソートします(降順)。 |
-k |
キーとして指定したフィールド(列)のみでソートします。例えば、-k 2なら2列目のデータを基準にソートします。 |
-t |
フィールドの区切り文字を指定します。デフォルトはスペースです。 |
-u |
重複を削除してユニークな行のみを出力します。 |
-o |
出力先ファイルを指定します。 |
-f |
大文字と小文字を区別せずにソートします。 |
-c |
ソートされているかをチェックし、ソートされていない場合は最初の箇所を報告します。 |
-m |
既にソートされている複数のファイルをマージします。 |
sort 実践
数値順にソートする:
sort -n ファイル名逆順でソートする:
sort -r ファイル名2列目を数値としてソートする:
sort -k 2 -n ファイル名カンマ区切りのファイルで、2列目を基準にソートする:
sort -t, -k2 -n ファイル名次のサンプルデータを用意しました。このデータには、果物の名前と数量がカンマ区切りで記載されています。
りんご,100
ばなな,20
ぶどう,300
みかん,50sortコマンドでこのデータの並び順を操作してみます。次はort -t, -k2 -n fruit_data.txtの実行結果です:
なな,20
みかん,50
りんご,100
いちご,200
ぶどう,300
あんず,500重複を削除する
sort ファイル名 | uniq(またはsort -u ファイル名)
sortコマンドは、ログファイルの分析、データの前処理、または単純にファイル内の行を整理する際に非常に便利です。複数のオプションを組み合わせることで、さまざまなソート条件を指定できます。
sort -k オプション詳細
sort -t, -k2,2nr の中の ,2 の部分について、
「-k2nr で良いのでは?」
と思いますよね。
-k オプションの構文詳細:
-k <start>[,<end>]start:ソートキーの開始フィールドend(省略可):ソートキーの終了フィールド- 同じ値を指定すれば、その1列だけがキーになる
-k2nr と -k2,2nr の違いは?:
| 記法 | 意味 |
|---|---|
-k2nr |
フィールド2以降すべてを使ってソート。ただし普通は先頭のフィールドで決まるので実質問題なし。 |
-k2,2nr |
フィールド2 だけ をキーとして、数値で降順にソート |
uniq
uniqコマンドは、テキストファイル内の連続する重複行をフィルタリングするために使用されます。重複行は、直前の行と完全に同じである場合にのみ検出されるため、一般的にuniqコマンドはsortコマンドと組み合わせて使用されます。
| オプション | 説明 |
|---|---|
-c |
各行が現れた回数を表示します。 |
-d |
重複している行のみを表示します。 |
-u |
重複していない行のみを表示します。 |
-i |
大文字と小文字の違いを無視して比較します。 |
-z |
入力と出力の行終端をNULL文字で扱います。 |
--count |
-cオプションと同様に、各行が現れた回数を表示します。 |
--repeated |
-dオプションと同様に、重複している行のみを表示します。 |
--unique |
-uオプションと同様に、重複していない行のみを表示します。 |
--ignore-case |
-iオプションと同様に、大文字と小文字の違いを無視して比較します。 |
--zero-terminated |
-zオプションと同様に、入力と出力の行終端をNULL文字で扱います。 |
uniq 実践
uniq処理の前にかならずsortコマンドで順番を整形してください。そうしないと重複削除がうまく機能しません。
重複行の数をカウントする:
sort ファイル名 | uniq -c重複している行のみを表示する:
sort ファイル名 | uniq -d重複していない行のみを表示する:
sort ファイル名 | uniq -u大文字と小文字を無視して重複行をフィルタリングする:
sort ファイル名 | uniq -iuniqコマンドはテキストの前処理やデータ分析など、さまざまなシナリオで有用です。特に、ログファイルやデータセットから重複を除外したり、特定のパターンがどれだけ頻繁に現れるかを確認したりする際に役立ちます。
cut
cut
コマンドは、テキストファイルやコマンド出力の各行から選択した部分を切り出して表示するためのコマンドです。主にテキストデータの列(フィールド)を扱うのに便利です。macOSやLinuxなどのUnix系OSで使用できます。
| オプション | 説明 |
|---|---|
-b |
(バイト単位での選択): 指定したバイト位置のデータを切り出します。 |
-c |
(文字単位での選択): 指定した文字位置のデータを切り出します。 |
-f |
(フィールド単位での選択): デリミタ(区切り文字)に基づいて列を指定して切り出します。 |
-d |
(デリミタの指定): フィールドのデリミタ(区切り文字)を指定します。デフォルトはタブです。 |
--output-delimiter |
(出力デリミタの指定): 出力時のフィールド区切り文字を指定します。 |
cutコマンド 実践
テキストファイルから1-5文字目を切り出す:
cut -c1-5 ファイル名CSVファイルから2列目をカンマで区切って抽出する:
cut -d',' -f2 ファイル名複数のフィールド(例えば、1列目と3列目)を抽出する:
cut -d',' -f1,3 ファイル名範囲指定でフィールドを抽出する(例えば、2列目から4列目):
cut -d',' -f2-4 ファイル名cut
コマンドはテキスト処理の際に非常に役立ちます。列に基づいたシンプルなデータの抽出に便利で、シェルスクリプトやデータ分析の初歩的な段階で頻繁に利用されます。
date
date
コマンドは、Unix系オペレーティングシステム(LinuxやmacOSなど)で使用されるコマンドラインユーティリティで、現在の日時を表示したり、設定したりするために使用されます。このコマンドは、様々なフォーマットで日時を表示するためのオプションを提供します。
現在の日時を表示
date特定のフォーマットで日時を表示(例: 年-月-日 時:分:秒)
date "+%Y-%m-%d %H:%M:%S"dateコマンドのフォーマットオプション
date
コマンドで使用できるフォーマットオプションの一部を以下に示します。
| オプション | 説明 |
|---|---|
%Y |
4桁の年(例: 2024) |
%m |
2桁の月(例: 01~12) |
%d |
2桁の日(例: 01~31) |
%H |
24時間制の2桁の時間(例: 00~23) |
%M |
2桁の分(例: 00~59) |
%S |
2桁の秒(例: 00~59) |
dateコマンドのオプション一覧
date
コマンドの使用可能なオプションの一覧を以下の表にまとめます。この表は、一般的なUnix系オペレーティングシステム(LinuxやmacOSなど)での使用を想定しています。オプションは実行環境によって異なる場合がありますので、詳細は各システムのmanページ(man dateコマンドで参照)を確認してください。
| オプション | 説明 |
|---|---|
-d、--date |
指定した日付/時間で日時を表示します。 |
-f |
指定したフォーマットで複数の日時を解析します。 |
-I |
ISO
8601形式で日時を表示します。オプションで時間の精度(hours、minutes、seconds、date)を指定できます。 |
-r |
指定したファイルの最終修正時刻を表示します。 |
-R |
RFC 2822形式で日時を表示します。メールなどで使用される形式です。 |
-u、--utc、--universal |
UTC(協定世界時)で日時を表示します。 |
--help |
使用方法を表示します。 |
--version |
バージョン情報を表示します。 |
特定の日時を表示
date -d "yesterday"ISO 8601形式で現在の日時を表示
date -Iseconds指定したファイルの最終修正時刻を表示
date -r filename.txtUTCで現在の日時を表示
date -u特定の日付でdateコマンドを使用する
次は、 2024年12月25日のタイムスタンプを取得する例です:
date -j -f "%Y-%m-%d" "2024-12-25" "+%s"-j
オプションは、日時を設定することなく、日時の変換や計算を行うために使用されます。つまり、システムの日時を変更せずに、特定の日時フォーマットの変換や計算を行いたい場合に便利です。
現在のUNIXタイムスタンプを取得
date "+%s"日時をファイル名に含める
次は、バックアップファイルの生成の例です:
tar -czf backup_$(date "+%Y-%m-%d_%H-%M-%S").tar.gz /path/to/directorydate
コマンドはシステムの設定やタイムゾーンに依存するため、表示される情報は実行環境によって異なります。また、システムの日時を変更するには、スーパーユーザー権限が必要です。
curl
GET
まずは簡単なGETのやり方です。
curl https://example.com/-v オプションを付与することで、 送信と受信のHTTP
リクエストのヘッダーを出力できます。
$ curl -vI https://example.com/さらに -I
オプションで、指定されたURLに対してHEADリクエストを送信し、レスポンスのヘッダーのみを表示します。
* Trying [64:ff9b::9979:42f3]:443...
...
> HEAD / HTTP/2
> Host: example.com
> User-Agent: curl/8.4.0
> Accept: */*
>
< HTTP/2 200
HTTP/2 200
< server: nginx
server: nginx
< date: Sun, 03 Mar 2024 11:06:59 GMT
date: Sun, 03 Mar 2024 11:06:59 GMT
< content-type: text/html
content-type: text/html
< content-length: 17419
content-length: 17419
< last-modified: Sun, 03 Mar 2024 00:34:27 GMT
last-modified: Sun, 03 Mar 2024 00:34:27 GMT
< etag: "65e3c593-440b"
etag: "65e3c593-440b"
< accept-ranges: bytes
accept-ranges: bytes
POST
次はPOSTリクエストのやり方です。
# 基本形
curl -X POST URL -d "param1=value1¶m2=value2"
# JSONを送る場合
curl -X POST URL \
-H "Content-Type: application/json" \
-d '{"key1":"value1","key2":"value2"}'
# ファイルアップロード
curl -X POST URL \
-F "file=@path/to/file.txt"JSONデータは基本、ダブルクオーテーションで囲みましょう。シングルクオーテーションで囲むと、サーバー側が対応してなくてエラーになる場合があります。
その他の注意点として、OAuthのBearer認証などで長いトークンを送信する場合は、かならずクオーテーションで囲むようにしましょう。囲まないと長い送信データは途中で切れてしまい、正しいリクエストが行えません。
curl -X POST 'https://example.com/endpoint' -H 'Content-Type: application/json;charset=utf-8' -d '{"id":"1", "name":"jojo"}' -H 'Authorization: Bearer XXXX'その他
UserAgent を変更するには -A オプションを使用します。
# UserAgentを指定
curl -A "Chazuke/2.1" https://example.com
# Cookieを指定
curl -b "username=chazuke; sessionid=123456" https://example.com
# Cookieファイルを読み込んでリクエスト
curl -b cookies.txt https://example.comjqコマンド
jq
コマンドを組み合わせると、jsonレスポンスを見やすく整形できます。
| アプリケーション | インストールコマンド |
|---|---|
| jq | brew install jq |
curl https://apppppp.com/jojo.json | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 43 100 43 0 0 128 0 --:--:-- --:--:-- --:--:-- 128
{
"name": "Jyotaro",
"stand": "The World"
}find
特定のディレクトリ下をファイル名で検索
特定の文字列を含むファイルを検索する例です。
find [ターゲットディレクトリ] -name '[ファイル名の文字列]'例:
find . -name '*arduino*'
find . -name 'arduino-yogurt-maker*'最近更新されたファイルを検索
更新から少ししか経過していないファイルを検索します。
find . -type f -mmin -10findとmvで一括移動
特定のファイルを検索して削除する例です。
find . -name 'IMG*' | xargs -I% mv -f % ~/.Trashfind 指定されたサイズ以上のファイルを検索
指定ディレクトリ内のファイルを再帰的に検査します。
find /path/to/directory -size +1Mカレントディレクトリ内で、特定の拡張子を除外し、詳細情報を表示したい場合:
find . -size +1M -not -name "*.gif" -exec ls -lh {} + | sort -k 5 -nfind 応用: 画像を一括リサイズする
#!/bin/bash
# ディレクトリ、サイズ制限(バイト単位)、リサイズ後の最大幅または高さを指定
TARGET_DIRECTORY="."
SIZE_LIMIT=2000000 # 2MBを超えるファイルを検索
MAX_DIMENSION=1500 # 最大幅または高さ
# 指定されたディレクトリ以下のjpg, jpeg, JPEG, pngファイルを検索し、それぞれに対して処理
find "$TARGET_DIRECTORY" \( -iname '*.jpg' -o -iname '*.jpeg' -o -iname '*.png' -o -iname '*.PNG' \) -print0 | while IFS= read -r -d $'\0' file; do
# ファイルサイズを取得
filesize=$(stat -f%z "$file")
# ファイルサイズが指定サイズを超える場合、リサイズ
if [ $filesize -gt $SIZE_LIMIT ]; then
echo "Resizing $filesize $file..."
sips -Z $MAX_DIMENSION "$file" --out "$file"
fi
done
echo "Done."このスクリプトは画像を上書きするので、実行前には必ずバックアップを取ってください。
find でファイルを更新する
fswatch
などのファイルウォッチツールでイベントを監視している場合、find
と組み合わせて touch
を使うことで、任意のファイル更新イベントをトリガーできて便利です。
find . -type f -name "*.yml" -exec touch {} +rename
macOSでは、ファイル名を一括変換したいときにFinderの機能を使って実現可能です。ですが私の場合、最近はFinderよりもターミナルを使うほうが何かと多く、ターミナルでのファイル名を一括で変更したいケースが出てきました。そこで見つけたのが
rename コマンドです。 rename
コマンドは2種類あるようですので注意してください。ここではbrewでインストールする
rename コマンドを解説していきます。
brewを使って rename をmacOSへインストールします。
$ brew install renamerenameコマンドの基本的な使い方
rename
コマンドは、次のような形に正規表現でマッチさせ一括置換できます。
$ rename 's/マッチさせる文字/変換する文字/' ファイル群テスト用のファイルを作成
いきなり本番で実行してしまうと致命的な損失になりかねないので、次のようなテストファイルを作成してテストを行なってください。
$ touch hoge.txt fuga.txt
$ ls
fuga.txt hoge.txtファイル名に接頭辞を追加する
ファイル名に接頭辞(prefix)を追加する例です:
$ rename 's/^/test_/' *.txt
$ ls
test_fuga.txt test_hoge.txtファイル名の接頭辞を削除する
ファイル名の接頭辞を削除する例です:
$ rename 's/^test_//' *.txt
$ ls
fuga.txt hoge.txtファイル名に接尾辞を追加する
ファイル名に接尾辞 (suffix) を追加する例です:
$ rename 's/.txt/_test.txt/' *.txt
$ ls
fuga_test.txt hoge_test.txtマッチング演算子を使わずに考えると簡単です。
拡張子を一括変更する
拡張子を一括変更する例です:
$ rename 's/.jpeg/.jpg/' *.jpeg大文字を小文字に一括変更する
たとえば次のような大文字名のファイルがあったとします。
$ ls
AU.csv BR.csv CA.csv CH.csv DE.csv次のように書くと、一括変更が可能です。オプション-fは上書きを強制します。
大文字を小文字に一括変更する例です:
$ rename -f 'y/A-Z/a-z/' *.csv
$ ls
au.csv br.csv ca.csv ch.csv de.csvrenameはperlの演算子を使用しているようで、s///はパターンマッチ・置換演算子、y///は変換演算子とのことです。大文字を小文字へ変換する場合、s///ではなくy///を使わないと変換できないのでご注意ください。
iconv
iconv
コマンドは、異なる文字コード間でテキストファイルのエンコーディングを変換するために使用されるコマンドラインユーティリティです。このコマンドは、多くのUNIX系オペレーティングシステムやLinuxディストリビューション、そしてmacOSで利用可能です。
iconv -f 元のエンコーディング -t 目的のエンコーディング 入力ファイル名 > 出力ファイル名-fまたは--from-codeオプションで元のエンコーディングを指定します。-tまたは--to-codeオプションで変換後のエンコーディングを指定します。- 入力ファイル名の後には、変換したいファイルの名前を指定します。
- 出力は標準出力に送られるので、リダイレクト (
>) を使用してファイルに保存することが一般的です。
エンコーディングの一覧表示
利用可能なエンコーディングの一覧を表示するには、以下のコマンドを使用します。
iconv -liconvの使用例
UTF-8のテキストファイルをShift_JISに変換する例:
iconv -f UTF-8 -t SHIFT_JIS input.txt > output.txtISO-8859-1のテキストファイルをUTF-8に変換する例:
iconv -f ISO-8859-1 -t UTF-8 input.txt > output.txt注意点:
- 変換できない文字がある場合、
iconvはエラーを出力します。これを回避するには、-cオプションを使用して、変換できない文字を出力から除外することができます。 - テキストデータに特定のエンコーディングが適用されていることを確認することは重要です。誤ったエンコーディングを指定すると、データが正しく変換されない可能性があります。
nkf
macOSでShift-JISのテキストファイルをUTF-8へ変更するため、シェルコマンド
nkf を使ったときのメモになります。
文字コードを変えるソフトは nkf の他にも
iconv が存在します。ですが iconv
ですとテキストファイルが何の文字コードを使っているか調べられないため、nkf
を使ったほうが便利です。
ここでは nkf
コマンドの簡単な使い方を解説していきます。
macOSに nkf をインストールしましょう。
$ brew install nkfインストールしたら nkf
コマンドが使えるかどうかチェックしましょう。
$ nkf -v
Network Kanji Filter Version 2.1.5 (2018-12-15)
Copyright (C) 1987, FUJITSU LTD. (I.Ichikawa).
Copyright (C) 1996-2018, The nkf Project.(へー、富士通が開発なさったんですねー)
文字コードを調べる
文字コードを調べるには -g または --guess
オプションを付与します。
こんな感じで文字コードが調べられます。
$ nkf -g data.csv
UTF-8文字コード変換オプション
次に文字コード変換オプションを説明します。 大文字が入力の文字コードで、小文字が出力の文字コードを表します。
| オプション(入力) | オプション(出力) | 意味 |
|---|---|---|
| -S | -s | Shift-JIS |
| -E | -e | EUC-JP |
| -W | -w | UTF-8 |
| -W16 | -w16 | UTF-16 |
UTF-8に変換して上書き保存
Shift-JISのテキストファイルをUTF-8へ変換してみます。
$ nkf -w --overwrite data.csvどうも入力の文字コードの指定はいらないみたいです。 自動で判別してくれてるようですねぇ。これは便利!
別名で保存
別名で保存したいときは次のようにすればOKです。
$ nkf -s data.csv > data_jis.csv簡単ですね!
catコマンドと組み合わせて、ファイルを上書きせずに表示する
次は、UTF-16のテキストデータをコンソールに出力する例です:
$ cat data_utf16.txt|cat -W16これで文字化けせずに中身を確認できるようになりました。
さらに詳しくは $ man nkf でお調べください。
fdupes
fdupes
は、ファイルシステム上で重複するファイルを探すためのコマンドラインツールです。ファイル名ではなく、ファイルの内容をハッシュで比較して重複判断を行います。さらには、以下のような機能も備わっています。
- 内容ベースの比較:
fdupesはファイル名やタイムスタンプではなく、ファイルの内容を比較して重複を検出します。 - 再帰的検索: サブディレクトリも含めたディレクトリ内のファイルを再帰的に検索できます。
- 削除オプション: 重複するファイルの削除を支援するオプションがあります。
まずはbrewでfdupesをmacOSへインストールします。
brew install fdupes1. 重複ファイルの検索:
指定したディレクトリ内の重複ファイルを探すには、単にfdupes [ディレクトリパス]を実行します。
fdupes /path/to/directory2. 再帰的検索:
サブディレクトリを含めて重複を検索するには、-rオプションを使用します。
fdupes -r /path/to/directory3. 重複ファイルの削除:
-dオプションを使うと、重複ファイルの一覧が表示され、どのファイルを保持するかを選択できます。
fdupes -d /path/to/directory4. プロンプトなしで重複ファイルを削除:
-Nオプションを追加すると、プロンプトなしで重複ファイルを自動的に削除します。
fdupes -dN /path/to/directoryfdupesは非常に便利ですが、重要なファイルを操作する場合は注意が必要です。特に、自動削除オプション(-dN)を使用する場合は、重要なデータのバックアップを取ることを強くお勧めします。
カレントディレクトリの中にあるファイルを再起的に重複かどうか判別し削除する
このスクリプトは、現在のディレクトリおよびその下のすべてのサブディレクトリで重複するファイルを検索します:
このスクリプトを実行すると、現在のディレクトリおよびそのすべてのサブディレクトリで重複ファイルを検索し、見つかった重複ファイルをプロンプトで確認した後で削除します。画像の重複を発見するために作成しましたが、画像以外のファイルの重複も検知するため実行する場合には十分気をつけてください。
#!/bin/bash
# 現在のディレクトリを対象に設定
TARGET_DIRECTORY=$(pwd)
# fdupesを使用して重複ファイルを再帰的に検出
echo "重複している画像を検索しています..."
duplicates=$(fdupes -r $TARGET_DIRECTORY)
# 重複が見つからなかった場合
if [ -z "$duplicates" ]; then
echo "重複する画像は見つかりませんでした。"
exit 0
fi
# 重複リストを表示
echo "以下のファイルが重複しています:"
echo "$duplicates"
# ユーザーに削除の確認
read -p "これらの重複するファイルの一方を削除しますか? [y/N] " response
if [[ "$response" =~ ^([yY][eE][sS]|[yY])$ ]]
then
# 重複ファイルの削除
echo "重複するファイルを削除しています..."
fdupes -rdN $TARGET_DIRECTORY
echo "重複するファイルが削除されました。"
else
echo "操作がキャンセルされました。"
filess
less
コマンドは、テキストファイルの内容をページ単位で表示し、前後に移動できるツールです。macOSやLinuxなどのUnix系OSで広く使われています。ここでは、基本的な操作方法といくつかの便利なオプションを紹介します。
| キー | 説明 |
|---|---|
Space |
次のページへ移動 |
b |
前のページへ移動 |
d |
半ページ分だけ次へ移動 |
u |
半ページ分だけ前へ移動 |
j |
1行下へ移動 |
k |
1行上へ移動 |
G |
ファイルの最後へ移動 |
g |
ファイルの先頭へ移動 |
/文字列 |
文字列を下方向へ検索 |
?文字列 |
文字列を上方向へ検索 |
n |
検索方向へ次の検索結果へ移動 |
N |
検索方向と逆へ次の検索結果へ移動 |
q |
less を終了 |
lessの便利なオプション
| オプション | 説明 |
|---|---|
-N |
行番号を表示 |
-R |
色付けされたテキストを正しく表示(例: Gitのdiff) |
-S |
長い行を折り返さずに表示 |
-X |
終了時に画面をクリアしない |
-F |
ファイルの内容が画面一杯に満たない時、自動的に終了 |
使用例
- ファイルを開く:
less ファイル名 - 行番号を表示しながらファイルを開く:
less -N ファイル名 - 色付けされたdiffを表示する:
git diff | less -R
less
コマンドは非常に強力で柔軟なツールです。これらの基本的な操作とオプションを覚えることで、テキストファイルの閲覧がずっと便利になります。
sed
macOSでのsedコマンドの基本的な使い方を説明します。sedはストリームエディタで、テキストファイルやパイプからの入力に対して行単位の編集を行うことができます。テキストの加工や置換処理など、データの前処理に非常に便利なツールです。
【sedまとめ】 sedの基本的な使い方
| コマンド | 説明 |
|---|---|
sed 's/検索パターン/置換文字列/' ファイル名 |
ファイル内で最初にマッチした検索パターンを置換文字列に置換します。 |
sed -i '' 's/検索パターン/置換文字列/' ファイル名 |
ファイル内で最初にマッチした検索パターンを置換文字列に置換し、ファイルを直接更新します(インプレース編集)。 |
sed 's/検索パターン/置換文字列/g' ファイル名 |
ファイル内の全てのマッチする検索パターンを置換文字列に置換します。 |
sed -n 'p' ファイル名 |
ファイルの内容を出力します(-nオプションは自動での出力を抑制し、pコマンドで明示的に出力を指示)。 |
sed '/検索パターン/d' ファイル名 |
検索パターンにマッチする行を削除します。 |
sed -E 's/正規表現/置換文字列/g' ファイル名 |
拡張正規表現を使用して、ファイル内の全てのマッチするパターンを置換文字列に置換します。 |
sed '1,5d' ファイル名 |
ファイルから1行目から5行目までを削除します。 |
sed 's/検索パターン/置換文字列/2' ファイル名 |
ファイル内で2番目にマッチした検索パターンのみを置換文字列に置換します。 |
【sed初級編】sedを使ってみよう
サンプルテキストファイルを用意しました。このファイルを使用して、sedコマンドの使用例をいくつか実行してみましょう。ファイルの内容は以下の通りです:
こんにちは、世界!
今日は良い天気ですね。
sedコマンドは強力です。
さようなら、世界!文字列の置換
sedコマンドを使って、「世界」を「プログラマー」に置換してみます。
sed 's/世界/プログラマー/g' sample_text.txt出力結果:
こんにちは、プログラマー!
今日は良い天気ですね。
sedコマンドは強力です。
さようなら、プログラマー!行の削除
次に、「良い天気」を含む行を削除してみます。
sed '/良い天気/d' sample_text.txt出力結果:
こんにちは、世界!
sedコマンドは強力です。
さようなら、世界!ファイルの直接編集(インプレース編集)
ファイルを直接編集し、再度「世界」を「プログラマー」に置換しますが、今回はファイルを直接更新します。
sed -i '' 's/世界/プログラマー/g' sample_text.txtファイルの内容が以下の通り変更されました:
こんにちは、プログラマー!
今日は良い天気ですね。
sedコマンドは強力です。
さようなら、プログラマー!sedコマンドはテキスト処理の際に非常に強力で、他のコマンドと組み合わせてパイプ(|)で使用されることが多いです。ここでは、sedを他のコマンドと組み合わせた典型的な使用例をいくつか紹介します。
ファイルから特定の行を抽出し、その行を編集
grepコマンドで特定のパターンにマッチする行を抽出し、sedでその行を編集する場合があります。
grep '特定のパターン' ファイル名 | sed 's/検索パターン/置換文字列/g'このコマンドは、ファイルから「特定のパターン」にマッチする行を見つけ出し、それらの行に含まれる「検索パターン」を「置換文字列」に置換します。
ログファイルから不要な情報を削除
ログファイルから特定のキーワードを含む行を除外したい場合に役立ちます。
cat ログファイル | sed '/不要なキーワード/d'このコマンドは、ログファイルから「不要なキーワード」を含む行を削除して表示します。
ファイルの特定のセクションだけを表示
sedを使ってファイルの特定の範囲の行だけを抽出することもできます。
sed -n '10,20p' ファイル名ただし、この操作をパイプで他のコマンドと組み合わせる場合は、抽出した行に対してさらに処理を加えたい場合に便利です。
複数の編集操作を組み合わせる
sedで複数の編集操作を一度に行うことができます。
echo "サンプルテキスト" | sed -e 's/サンプル/テスト/' -e 's/テキスト/データ/'このコマンドは、「サンプル」を「テスト」に、そして「テキスト」を「データ」に置換します。
パイプライン内でのデータ加工
複雑なデータ加工の一環として、sedを使って一時的な修正を加えた後、さらにawkやsortなどのコマンドで処理を行うことがあります。
cat データファイル | sed 's/不要な部分//' | sort | uniqこの例では、まずsedを使って「不要な部分」を削除し、その後sortで並び替え、uniqで重複行を削除しています。
具体的に実行してみましょう。サンプルデータファイルを作成しました。このファイルは人名のリストを含み、各行には「名前:」という不要な部分が含まれています。ファイルの内容は以下の通りです:
名前:山田太郎
名前:鈴木一郎
名前:高橋花子
名前:山田太郎
名前:佐藤あきら
名前:鈴木一郎このデータを使って、「cat データファイル | sed ‘s/不要な部分//’ | sort | uniq」のコマンド例を実際に試してみます。目的は「名前:」を取り除き、名前をアルファベット順に並び替え、重複を削除することです。
実際のコマンドは以下のようになります:
cat sample_data.txt | sed 's/名前://g' | sort | uniqこのコマンドを実行すると、以下のような結果が得られます:
山田太郎
鈴木一郎
高橋花子
佐藤あきらこの結果から、各行から「名前:」が取り除かれ、名前がアルファベット順に並び替えられ、重複が削除されました。
日本語データのソート
まず、この日本語データを使って単純なソートを実行する場合、sortコマンドは以下のように使用します:
sort fruit_data.txtこのコマンドは、データを辞書順にソートします。
フィールドを指定したソート
各行をカンマで区切られたフィールドとして扱い、特定のフィールド(この場合は数量)に基づいてソートを行います。sortコマンドでは-tオプションでフィールドの区切り文字を指定し、-kオプションでソートの基準となるフィールド番号を指定します。
数量に基づいてソートする場合のコマンドは以下の通りです:
sort -t, -k2,2n fruit_data.txt-t,はフィールドの区切り文字がカンマであることを指定します。-k2,2nは2番目のフィールド(数量)に基づいて数値順にソートすることを指定します。
【sed現場編】nginxのログファイル解析
次の形でnginxのエラーログかあったとします。
2024/03/13 23:44:54 [error] 3062295#3062295: *10304 open() "/dir/path/.well-known/openid-configuration" failed (2: No such file or directory), client: 165.232.170.165, server: k.araisun.com, request: "GET /.well-known/openid-configuration HTTP/1.1", host: "k.araisun.com"ホスト名とエラーでフィルタリングして、ファイル名だけを抽出する
grep "host: \"k.araisun.com\"" /var/log/nginx/error.log.1 | grep "failed" | sed -E 's/.* open\(\) "([^"]+)".*/\1/g'特定のディレクトリ名を除外して、ファイル名だけを抽出する
grep -v ".well-known" /var/log/nginx/error.log.1 | sed -E 's/.* open\(\) "([^"]+)".*/\1/g' | uniq -c | sort grepコマンドの-vオプションを使うと、特定のパターンを含む行を除外できます。結果を出力する前に、uniq -cによって重複行をまとめ、カウントさせています。そしてsortコマンドで、重複の数が少ない順に並べ替えて出力します。
tail
tailコマンドは、Unix系オペレーティングシステムにおいて、テキストファイルの末尾の部分を表示するために使用されます。デフォルトでは、ファイルの最後の10行を出力しますが、この行数はオプションで調整することができます。
tail [オプション] [ファイル名]ここで、よく使用されるオプションは以下の通りです:
| オプション | 説明 |
|---|---|
-n オプション |
表示する行数を指定します。-n 5のように使用し、最後の5行を表示します。 |
-f オプション |
ファイルの末尾に追加されたデータをリアルタイムで表示します。 |
とくに-fオプションは、ログファイルの監視に便利です。
ファイルの最後の10行を表示する
tail ファイル名ファイルの最後の5行を表示する
tail -n 5 ファイル名ファイルの末尾をリアルタイムで監視する
tail -f ファイル名tailコマンドは、ログファイルの監視や、大きなファイルから最新の情報を素早く取得する際に特に便利です。
tailコマンドは他のUnixコマンドと組み合わせて使用されることが多く、その応用は非常に多岐にわたります。以下に、いくつかの一般的な例を紹介します。
grepとの組み合わせ
特定のパターンを含む行のみをファイルの末尾から表示します。ログファイルから特定のエラーメッセージを探す場合などに便利です。
tail -f ファイル名 | grep "検索パターン"awkとの組み合わせ
tailで取得した出力をさらに処理し、特定のフォーマットに変換したり、特定のデータを抽出したりします。
awkを使用して特定のカラムのみを表示する例:
tail -n 10 ファイル名 | awk '{print $1}'sedとの組み合わせ
sedを使用して特定の文字列を置換する例:
tail -n 10 ファイル名 | sed 's/置換前の文字列/置換後の文字列/g'sortとの組み合わせ
ファイルの最後の部分の行を特定の基準でソートして表示します。
tail -n 10 ファイル名 | sortheadとの組み合わせ
ファイルの最後の部分から特定の行数を取得した後、さらにその中の最初の数行だけを表示します。例えば、ファイルの最後の20行のうち、最初の5行だけを表示する場合に便利です。
tail -n 20 ファイル名 | head -n 5これらの応用例は、ログファイルの監視、データ分析、システム管理タスクの自動化など、多岐にわたるタスクに利用することができます。
awkと組み合わせて色をつける
次は、ログレベル毎に色分けして表示してくれるスクリプトで、とても便利です。
tail -f /path/to/logfile | awk '
{
if ($0 ~ /ERROR/) {
print "\033[31m" $0 "\033[39m" # 赤色
} else if ($0 ~ /WARN/) {
print "\033[33m" $0 "\033[39m" # 黄色
} else if ($0 ~ /INFO/) {
print "\033[32m" $0 "\033[39m" # 緑色
} else {
print $0
}
}'ログにハイライト表示してくれるツールはありますが、awkを使った方法でも十分で、カスタマイズも簡単です。シェルスクリプト化しておいて、簡単に呼び出せるようにすると良いと思います。例えば以下のようなシェルスクリプトを
log_colorizer.sh として保存します。
#!/bin/bash
# ログファイルパスを引数から取得
LOG_FILE=$1
# ログレベルを変数で管理
LEVEL_ERROR="ERROR"
LEVEL_WARN="WARN"
LEVEL_INFO="INFO"
LEVEL_DEBUG="DEBUG"
LEVEL_CUSTOM="CUSTOM"
# tail コマンドでログファイルを監視し、awk で色付け
tail -n 1000 -f "$LOG_FILE" | awk -v error="$LEVEL_ERROR" -v warn="$LEVEL_WARN" -v info="$LEVEL_INFO" -v debug="$LEVEL_DEBUG" -v custom="$LEVEL_CUSTOM" '
{
if ($0 ~ error) {
print "\033[31m" $0 "\033[39m" # 赤色
} else if ($0 ~ warn) {
print "\033[33m" $0 "\033[39m" # 黄色
} else if ($0 ~ info) {
print "\033[32m" $0 "\033[39m" # 緑色
} else if ($0 ~ debug) {
print "\033[34m" $0 "\033[39m" # 青色
} else if ($0 ~ custom) {
print "\033[35m" $0 "\033[39m" # 紫色
} else {
print $0
}
}'実行権限を追加して ./log_colorizer.sh /path/to/log/file
で実行すれば、下図のようにログレベルに応じて色付け表示されてとても見やすくなります。
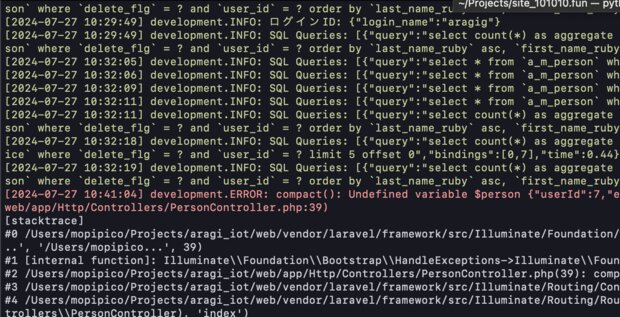
ログ表示をレベル制限してハイライト表示できる ctail.sh
先ほどご紹介した log_colorizer.sh
をさらに発展させてみました。ctail.sh
と名づけ、bin ディレクトリなどに保存して
ctail /path/to/log/file WARN
のようにして、実行しやすくするととても便利です!
#!/bin/bash
# ログレベルとログファイルパスを引数から取得
LOG_FILE=$1
LOG_LEVEL=$2
# ログレベルの優先度を定義
LEVEL_ERROR="ERROR"
LEVEL_WARN="WARN"
LEVEL_INFO="INFO"
LEVEL_DEBUG="DEBUG"
LEVEL_CUSTOM="mopi"
# ログレベルの優先度を設定
declare -A LEVELS
LEVELS=([mopi]=1 [ERROR]=2 [WARN]=3 [INFO]=4 [DEBUG]=5)
# tail コマンドでログファイルを監視し、awk で色付けとフィルタリング
tail -n 1000 -f "$LOG_FILE" | awk -v error="$LEVEL_ERROR" -v warn="$LEVEL_WARN" -v info="$LEVEL_INFO" -v debug="$LEVEL_DEBUG" -v custom="$LEVEL_CUSTOM" -v min_level="${LEVELS[$LOG_LEVEL]}" '
function level_priority(level) {
if (level == "mopi") return 1;
if (level == "ERROR") return 2;
if (level == "WARN") return 3;
if (level == "INFO") return 4;
if (level == "DEBUG") return 5;
return 999; # 不明なレベルは最下位扱い
}
{
log_level = 999;
if ($0 ~ custom) {
log_level = level_priority("mopi");
color = "\033[35m"; # 紫色
} else if ($0 ~ error) {
log_level = level_priority("ERROR");
color = "\033[31m"; # 赤色
} else if ($0 ~ warn) {
log_level = level_priority("WARN");
color = "\033[33m"; # 黄色
} else if ($0 ~ info) {
log_level = level_priority("INFO");
color = "\033[32m"; # 緑色
} else if ($0 ~ debug) {
log_level = level_priority("DEBUG");
color = "\033[34m"; # 青色
} else {
log_level = level_priority("DEBUG");
color = "\033[0m"; # デフォルト
}
# 指定したログレベル以上のもののみを表示
if (log_level <= min_level) {
print color $0 "\033[39m";
}
}
'使い方は以下の通り、最後に WARN
などのログレベルを付与することで、レベル以下の不要なログをフィルタリングできます。
./ctail.sh /path/to/log/file WARNawk
awk
は、テキストファイルの操作やパターンマッチングを行うための強力なツールです。ここでは、awkの基本的な使い方および応用編を忘備録として残しておきます。
基本的な構文
awk 'pattern {action}' file特定の列を抽出する
ファイル data.txt から第1列と第3列を表示する
awk '{print $1, $3}' data.txtawk のデフォルトで解釈される列のセパレータはスペースまたはタブ文字です。これにより、空白やタブで区切られたフィールドを処理することができます。
パターンにマッチする行を抽出する
data.txt から “apple” を含む行を表示する
awk '/apple/' data.txt条件に基づいて処理を行う
第2列が50以上の行を表示する
awk '$2 >= 50' data.txtフィールドセパレータを指定する
カンマ区切りのファイル data.csv から第2列を表示する
awk -F ',' '{print $2}' data.csvBEGIN と END ブロックを使う
ファイルの先頭と末尾で処理を行う
awk 'BEGIN {print "Start of file"} {print $0} END {print "End of file"}' data.txt複数条件を使用する
第2列が50以上かつ第3列が100以下の行を表示する
awk '$2 >= 50 && $3 <= 100' data.txt-v オプションは awk
コマンドで使用され、シェル変数の値を awk
の変数として使用するために使われます。これにより、シェルスクリプト内の変数を
awk スクリプトに渡すことができます。
以下に、-v オプションの使用方法を説明します。
シェルスクリプト例
シェルスクリプト内で定義された変数
LEVEL_ERROR、LEVEL_WARN、LEVEL_INFO、LEVEL_DEBUG、LEVEL_CUSTOM
を awk スクリプト内で使う例です。
LEVEL_ERROR="ERROR"
LEVEL_WARN="WARN"
LEVEL_INFO="INFO"
LEVEL_DEBUG="DEBUG"
LEVEL_CUSTOM="CUSTOM"
awk -v error="$LEVEL_ERROR" -v warn="$LEVEL_WARN" -v info="$LEVEL_INFO" -v debug="$LEVEL_DEBUG" -v custom="$LEVEL_CUSTOM" '
{
if ($0 ~ error) {
print "\033[31m" $0 "\033[39m" # 赤色
} else if ($0 ~ warn) {
print "\033[33m" $0 "\033[39m" # 黄色
} else if ($0 ~ info) {
print "\033[32m" $0 "\033[39m" # 緑色
} else if ($0 ~ debug) {
print "\033[34m" $0 "\033[39m" # 青色
} else if ($0 ~ custom) {
print "\033[35m" $0 "\033[39m" # 紫色
} else {
print $0
}
}
' inputfileこのスクリプトをtailと組み合わせるとログレベルに応じて色付けできて便利です。
シェルスクリプトの説明
-v error="$LEVEL_ERROR"の部分は、シェル変数LEVEL_ERRORの値をawkの変数errorに設定しています。他の変数(warn,info,debug,custom)についても同様です。$0 ~ errorの部分は、現在の行($0)がerrorのパターンにマッチするかどうかを確認しています。- 各条件にマッチした場合、対応する色で行を表示します。
このようにして、シェルスクリプト内の変数を awk
スクリプトに渡し、条件に基づいて異なる色で行を出力することができます。
diff (colordiff)
colordiffは、diffの出力を色分けして表示します。これにより、差分の部分(追加、削除、変更)が視覚的に分かりやすくなります。colordiffは、基本的にはdiffコマンドのラッパー(フロントエンド)です。内部でdiffを実行し、その出力に色を付けて表示しているため、機能やオプションはdiffと同じです。
macOSであれば brew で colordiff
をインストールできます。
brew install colordiffローカルファイル同士の比較
ローカルファイル同士の比較は通常のdiffと同じコマンドを使用し、colordiffを代わりに使うだけです。
colordiff file1.txt file2.txt最も一般的な形式で表示
-u (Unified format)
オプションで差分を統合形式で表示します。
colordiff -u file1.txt file2.txt再帰的に比較
-r (Recursive)
オプションでディレクトリ間で再帰的に比較を行います。
colordiff -ur dir1 dir2空白の違いを無視して比較
-w (Ignore whitespace)
オプションで空白の違いを無視します。
colordiff -uw file1.txt file2.txt大文字・小文字の違いを無視して比較
-i (Ignore case)
オプションで大文字と小文字の違いを無視します。
colordiff -ui file1.txt file2.txt空行の違いを無視して比較
-B (Ignore blank lines)
オプションで空行の違いを無視します。
colordiff -uB file1.txt file2.txtディレクトリ内のファイルを再起的に比較
ディレクトリ内のファイル群を一括で比較できます。
colordiff -r ディレクトリ1 ディレクトリ2このコマンドは、ディレクトリ1 と
ディレクトリ2
内のファイルを再帰的に比較し、差分を表示します。diff
はファイル名が一致するファイル同士を比較し、異なる部分を表示します。
左右に分割して差分表示
diff コマンドの --side-by-side
オプションを利用することで左右分割表示が可能です。
colordiff --side-by-side file1 file2リモートファイルとの比較
リモートファイルとローカルファイルを比較するには、sshを使ってリモートファイルを取得し、diffまたはcolordiffで比較します。
以下の方法が一般的です。
方法1: scpを使用する
リモートファイルを一時的にローカルにコピーしてから比較する方法です。
scp user@remote_host:/path/to/remote_file.txt /tmp/remote_file.txt
colordiff /tmp/remote_file.txt local_file.txt方法2: sshを使って直接比較
sshを使用してリモートファイルの内容を取得し、diffで比較することもできます。
diff <(ssh user@remote_host 'cat /path/to/remote_file.txt') local_file.txt | colordiffこの方法であれば、リモートファイルを一時的にローカルに保存せずに直接比較できます。
tar
この記事ではtarコマンドを使ってmacOSのバックアップ管理を行う方法を解説いたします。
macOSのバックアップにはTime Machineを使うのが一般的ですが、別途にTime Machine用のコンピューターを用意したりと面倒です。そこでtarコマンドを使うと便利です。tarコマンドは指定したディレクトリを一つのアーカイブにまとめてくれるシェルコマンドです。gzipやtar.bz2といった圧縮も行ってくれます。また、指定したディレクトリや拡張子を除外してアーカイブすることも簡単です。私は定期的にmacOSの中の重要なフォルダを、tarコマンドを使って圧縮しUSBメモリに保存することでバックアップしてます。最小限で必要なファイルのみをバックアップしてるので、圧縮しても20GBにも満たない程度です。ですから比較的短時間でバックアップ作業は終わります。シンプルなので精神衛生上も安心できます。
tarで指定ファイル・ディレクトリを除外してtar.bz2で圧縮する方法
それでは、tarでmacOSの指定ファイル・ディレクトリを除外して、tar.bz2で圧縮する方法をご紹介いたします。ズバリ次のコマンドを使ってます。
$ tar --exclude "[Bb]uild" --exclude "html" --exclude "Pods" --exclude ".git" --exclude ".gradle" --exclude "*.apk" --exclude "*.aab" --exclude "*.mp4" --exclude "*.avi" -vcjf projects_bk.tar.bz2 Projects実行すると、カレントディレクトリにあるProjectsディレクトリを
projects_bk.tar.bz2
というファイル名でアーカイブされます。
tarのバージョン
私の環境下でのtarのバージョンは次のとおりです。
$ tar --version
bsdtar 3.5.3 - libarchive 3.5.3 zlib/1.2.11 liblzma/5.0.5 bz2lib/1.0.8 –excludeオプション
--exclude
で指定したディレクトリ名や、ファイル名は除外されます。正規表現のワイルドカードなどが使えます。私はプログラミングをよく行うので、Buildしたり、Gitを使ったりします。それらは比較的大きな容量になってしまいますので、バックアップ対象からは除外させてます。ソースコードや文章ファイルなどが生きていれば、後からなんとかなりますので、そういったものは大切にバックアップするようにします。
-vcjfオプション
-vcjfオプションですが、まず、cvfは次の意味になります。
| 記号 | 意味 |
|---|---|
| c | 新規作成(圧縮)する |
| v | 処理したファイルを標準出力する |
| f | 指定したファイル名でアーカイブ |
そしてjオプションは次のとおり圧縮形式を表します。
| 記号 | 意味 |
|---|---|
| j | bzip2を通して圧縮 |
| z | gzipを通して圧縮 |
| J | xz compressを通して圧縮 |
対象ディレクトリを指定する際の注意点
アーカイブしたい対象ディレクトリを指定する際に、絶対パスで指定しないようにしてください。 展開するときも絶対パスで展開されてしまい、既存のディレクトリが消滅してしまう恐れがあるからです。 この問題の解決方法として、対象ディレクトリの親ディレクトリまで移動してから相対パスでアーカイブするようにします。
バックアップシェルスクリプトの例
たとえば、次のようなアーカイブを行うシェルスクリプト作って、cronなどに登録して定期的にバックアップ処理すると便利でしょう。このシェルスクリプトでは、アーカイブファイルをUSBメモリなどに移動する処理までは書いてませんので、ご注意ください。
#!/bin/bash
DIR1='memo'
DIR2='Documents'
DIR3='Projects'
BKFILE1='memo_bk.tar.bz2'
BKFILE2='document_bk.tar.bz2'
BKFILE3='projects_bk.tar.bz2'
cd ~/
pwd
# 絶対パスでアーカイブしてはダメ!っ絶対に!->展開するときも絶対パスで展開されてしまう!!!
# ディレクトリを移動してから相対パスでアーカイブすること!!!
tar --exclude "[Bb]uild" --exclude "html" --exclude "Pods" --exclude ".git" --exclude ".gradle" --exclude "*.apk" --exclude "*.aab" --exclude "*.mp4" --exclude "*.avi" -vcjf ${BKFILE1} ${DIR1}
tar --exclude "[Bb]uild" --exclude "html" --exclude "Pods" --exclude ".git" --exclude ".gradle" --exclude "*.apk" --exclude "*.aab" --exclude "*.mp4" --exclude "*.avi" -vcjf ${BKFILE2} ${DIR2}
tar --exclude "[Bb]uild" --exclude "html" --exclude "Pods" --exclude ".git" --exclude ".gradle" --exclude "*.apk" --exclude "*.aab" --exclude "*.mp4" --exclude "*.avi" -vcjf ${BKFILE3} ${DIR3}アーカイブ(tar.bz2)を解凍する方法
実際にアーカイブされたバックアップファイルを解凍するにはどうすれば良いでしょうか?
tar
コマンドのオプションを使って解凍することも可能ですが、macOSならFinderから
tar.bz2
ファイルをダブルクリックすることで解凍できます。万が一同じディレクトリ名が存在していたら、サフィックスを自動で付けて上書きしないよう安全に解凍してくれます。
さいごに
現在私は、この記事を執筆しながらバックアップファイルを新しいMac環境へ展開中です。2017年モデルのMacBook Proから2022モデルのMacBook Airへ乗り換えました。はじめてのM2コアですが、消費電力も少なくサクサク動いて快適です!どちらのMacのSSD容量も256GBです。これでアプリ開発やプログラミング、サイト制作してます。容量が少ないように思われますが、定期的にキャッシュを削除したり、動画や音楽などメディアファイルはクラウド上、またはUSBメモリへ移動させるようにしているので問題ないです。広い物置があると、モノを溜め込みすぎて管理することが大変になるのと同じです。使わないものは手元にできるだけ置かないようにすることで、バックアップ対象も最小限に抑えることができるはずです。

expect
expect
は、対話型のコマンドライン操作を自動化するためのツールおよびスクリプト言語です。特に、SSH接続やパスワード入力など、標準的な自動化ツールでは対処しにくい、対話型の操作が必要な場面で使用されます。
具体的には、次のような動作を行うことができます。
対話型プロセスの自動化
コマンドを実行し、その結果を監視して特定のキーワード(例: “password:”)が表示されたときに、事前に指定した入力(例: パスワード)を送信することができます。
タイミングを考慮した自動操作
SSH接続やその他の対話型セッションのステップに応じて、適切なタイミングで次のコマンドや入力を送信します。
人の手で行う操作のスクリプト化
対話型のCLI(コマンドラインインターフェース)操作をスクリプト化することで、繰り返し作業を効率化できます。
expect
は、通常のシェルスクリプトでは対応が難しい、ユーザーの入力を待つプログラム(SSH、su、passwd
など)に対して自動的に操作を行うのに非常に便利です。
主な用途
- SSHや
suなどのパスワード入力を自動化 - 対話型インストーラーや設定プロセスの自動化
- テストの自動化(対話型のプログラムをテストする際)
セキュリティ上の観点から、パスワードをスクリプト内に含めることはリスクがあるため、その運用には十分注意が必要です。
ssh
接続と su - root
のパスワード入力を自動化し、ログイン後のシェル操作を一発でやる
以下のようにスクリプトを作成して、ssh 接続と
su - root
のパスワード入力を自動化することが可能です。ただし、su
コマンドのパスワードを自動化することはセキュリティリスクがあるため、慎重に運用する必要があります。
まずは expect
コマンドを利用して、自動化を行うスクリプトを作成します。
expect
がインストールされているか確認し、必要に応じてインストールしてください(macOSの場合はbrew install expect)。
スクリプト例
以下のスクリプトを作成して、ssh_su.sh
という名前で保存します。
#!/usr/bin/expect
set timeout -1
set ssh_password "your_ssh_password"
set su_password "your_su_password"
# SSH 接続
spawn ssh user_name@your_hostname
expect "password:"
send "$ssh_password\r"
# su - root 実行
expect "$ "
send "su - root\r"
expect "Password:"
send "$su_password\r"
# ディレクトリ移動
expect "# "
send "cd /home/user_name\r"
# インタラクティブモードに移行
interactこのスクリプト内の expect "Password:"
は文字列一致なので注意してください。例えばプロンプトが日本語にローカライズドされている時は
expect "パスワード:"
と変更する必要があるかもしれません。
スクリプトに実行権限を与えます。
chmod +x ssh_su.shスクリプトを実行します。
./ssh_su.shこのスクリプトを実行すると、ssh 接続後に自動的に
su - root
に切り替わり、指定のディレクトリに移動します。
convert
macOSでImageMagickを使用するための基本的な手順をご紹介いたします。macOSには画像加工処理のできるsipsコマンドが標準で備わっていますが、Linuxをはじめ他のOSでも使えるImageMagickなので、覚えて損はないと思います。
macOSにImageMagickをインストールするには、Homebrewを使用するのが一般的です。まずはHomebrewがインストールされていることを確認し、次に以下のコマンドを実行します。
| パッケージ | バージョン | インストールコマンド |
|---|---|---|
| ImageMagick | 7.1.1-29 | brew install imagemagick |
ImageMagickの基本的な使い方
ImageMagickには多数のオプションがあり、画像の変換、編集、作成などが可能です。ここでは、基本的な使い方とよく使用されるオプションを紹介します。
| コマンド | 説明 | 例 |
|---|---|---|
convert |
画像の形式を変更する | convert input.png output.jpg |
mogrify |
画像を上書きして変更する | mogrify -resize 100x100 input.jpg |
-resize |
画像のサイズを変更する | convert input.jpg -resize 50% output.jpg |
-crop |
画像を切り抜く | convert input.jpg -crop 300x300+10+20 output.jpg |
-gravity |
位置を指定して操作する(例: クロップ、トリム) | convert input.jpg -gravity center -crop 100x100+0+0 output.jpg |
-quality |
JPEGの品質を指定する | convert input.png -quality 80 output.jpg |
-rotate |
画像を回転させる | convert input.jpg -rotate 90 output.jpg |
-colorspace |
色空間を変更する | convert input.jpg -colorspace Gray output.jpg |
【実践編】HEIC画像をJPEGに変換する
iPhoneで撮った写真が HEIC
になってしまうので、jpgへ変換したい場合は次のように実行します。
convert input.heic output.jpgまたは、
magick input.heic output.jpg次は、アスペクト比を保ったまま縦横の指定サイズ内に収める、一括変換コマンドです。あらかじめ、resizedディレクトリを作成しておきます。変換後のファイルはそこへ格納されます。
mogrify -resize '1500x1500>' -path resized *.jpg *.png次は、ディレクトリ内の .heic と .HEIC
を一括でJPEGに変換するワンライナーです:
for file in *.[hH][eE][iI][cC]; do convert "$file" -quality 80 "${file%.*}.jpg"; donemacOSの.zshrcにエイリアスを設定しておくと非常に便利です。iPhoneの写真をmacOSで使いたい場合に、大抵heicファイルですから。それらを一括でjpg変換できます。
alias heic='for file in *.[hH][eE][iI][cC]; do magick "$file" -quality 80 -define jpeg:extent=2MB "${file%.*}.jpg"; done'【実践編】4:3画像を16:9のアスペクト比でくり抜く
magick input.heic -gravity center -crop 16:9 +repage output.jpg【応用編】アスペクト比を保ってスケール変換
よく使う処理は、次のように関数にまとめておくと便利です。アスペクト比を保って画像のスケール変更し、さらにpngファイルの場合は背景を白にしてjpgファイルへ出力します。
#!/bin/bash
scale_craft() {
input_path="$1"
width="$2"
height="$3"
quality="$4"
output_path="$5"
# 出力先ディレクトリを作成(存在しない場合)
output_dir="$(dirname "$output_path")"
mkdir -p "$output_dir"
magick "$input_path" -resize "${width}x${height}" -background white -alpha remove -alpha off -quality "$quality" "$output_path"
# local input_path="$1"
# local scale="$2" # 例: 0.5
# local quality="$3" # 例: 85
# local output_path="$4"
#
# magick "$input_path" -resize "$(echo "$scale*100" | bc)%" -quality "$quality" "$output_path"
}
# ここからがテストコード
if [[ "${BASH_SOURCE[0]}" == "$0" ]]; then
input="/Users/mopipico/Desktop/a.png"
output="/Users/mopipico/Desktop/out.jpg"
scale_craft "${input}" 1200 800 85 "${output}"
#scale_craft "${input}" 0.5 85 "${output}"
fi
【応用編】文字を入れてサムネを作る
#!/bin/bash
function thumb_craft() {
local TITLE="$1"
local SUB_TITLE="$2"
local BICOLOR="$3"
local TEXT_COLOR="$4"
local OUTPUT="$5"
# フォント(システムに応じて調整)
FONT_TITLE="/System/Library/Fonts/ヒラギノ角ゴシック\ W5.ttc"
FONT_SUB="/System/Library/Fonts/ヒラギノ角ゴシック\ W5.ttc"
#FONT_TITLE="/Users/mopipico/Library/Fonts/yawarakadragon.otf"
#FONT_SUB="/Users/mopipico/Library/Fonts/yawarakadragon.otf"
# 画像サイズ
WIDTH=1200
HEIGHT=630
if [[ -z "$SUB_TITLE" ]]; then
# サブタイトルがない場合:タイトルを中央に
magick -size ${WIDTH}x${HEIGHT} canvas:"${BICOLOR}" \
-font "$FONT_TITLE" -fill "$TEXT_COLOR" -pointsize 64 -gravity center \
-annotate +0+0 "$TITLE" \
"$OUTPUT"
else
# サブタイトルがある場合:タイトルを上に、サブタイトルを下に
magick -size ${WIDTH}x${HEIGHT} canvas:"${BICOLOR}" \
-font "$FONT_TITLE" -fill "$TEXT_COLOR" -pointsize 64 -gravity center \
-annotate +0-50 "$TITLE" \
-font "$FONT_SUB" -pointsize 32 -annotate +0+60 "$SUB_TITLE" \
"$OUTPUT"
fi
}
# ここからがテストコード
if [[ "${BASH_SOURCE[0]}" == "$0" ]]; then
# YAMLファイルのパス
for YAML_FILE in /somewhere/*.yml; do
# ディレクトリとベースファイル名を取得
dir_name=$(dirname "$YAML_FILE")
base_name=$(basename "$YAML_FILE" .yml)
# YAMLから値を読み取る
title=$(yq '.title' "$YAML_FILE")
sub_title=$(yq '.sub_title' "$YAML_FILE")
bgcolor=$(yq '.bgcolor' "$YAML_FILE")
text_color=$(yq '.text_color' "$YAML_FILE")
# 出力ファイルパス(同じディレクトリに出力)
output="${dir_name}/${base_name}.png"
# サムネイル生成
thumb_craft "${title}" "${sub_title}" "${bgcolor}" "${text_color}" "${output}"
done
fi
top
topコマンドは、UNIX系オペレーティングシステム(macOSを含む)で、システムのプロセスとリソース使用状況をリアルタイムで表示するために使用されます。このコマンドは、CPUやメモリの使用状況、実行中のプロセス、システムアップタイムなど、システムのパフォーマンスに関する多くの情報を提供します。
topコマンドを実行すると、システムの現在の状態が表示されます。この表示は自動的に更新され、最新の情報を提供し続けます。
toptopコマンドの操作
topコマンドを実行中には、いくつかのキーボードショートカットで操作を行うことができます。
| キー | 説明 |
|---|---|
q |
topを終了します。 |
e |
単位を変更します(例:メモリ表示をK、M、Gで切り替えます)。 |
r |
プロセスの優先順位(renice値)を変更します。 |
k |
プロセスを終了(kill)します。プロセスIDを入力する必要があります。 |
オプションとしてよく使われるもの
| オプション | 説明 |
|---|---|
-n |
更新の頻度を秒単位で指定します。例えば、top -n 2は2秒ごとに情報を更新します。 |
-o |
特定の列を基準にプロセスをソートするために使用します。例えば、top -o cpuはCPU使用率でプロセスをソートします。 |
-U |
特定のユーザーのプロセスのみを表示します。例えば、top -U usernameはusernameに該当するユーザーのプロセスのみを表示します。 |
これはtopコマンドの基本的な使い方とオプションの一部ですが、詳細なオプションや機能については、man topコマンドを使用してマニュアルページを参照してください。
htop
topコマンドが見づらい場合はhtopがおすすめ。グラフィカルなCLIで表示してくれる。
brew install top でmacOSにもインストール可能だ。
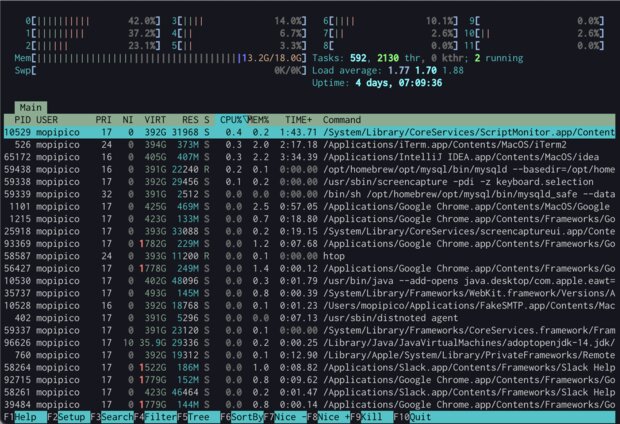
free
メモリを使用量を確認したいだけならば、シンプルなfreeコマンドがおすすめ。
free -hps
ps
コマンドは、現在実行中のプロセスのスナップショットを表示するUNIX系システムのコマンドです。以下の表に、よく使用されるオプションとその説明をまとめました。
psコマンドのオプション
| オプション | 説明 |
|---|---|
-A, -e |
全てのプロセスを表示します。 |
-a |
ターミナルに関連付けられたプロセスを表示します。デーモンプロセスなどのターミナルに関連付けられていないプロセスは除外されます。 |
-u <ユーザー名> |
指定したユーザー名のプロセスを表示します。 |
-x |
ターミナル制御なしでプロセスを表示します。 |
-f |
フルフォーマットで表示します。ユーザー名、プロセスID、親プロセスID、メモリ使用量、ターミナル番号、プロセスの状態など、より詳細な情報を含みます。 |
-o <フィールド名> |
出力をカスタマイズして、指定したフィールドのみを表示します。例えば、pid,comm
を指定すると、プロセスIDとコマンド名のみが表示されます。 |
-p |
指定したプロセスIDのプロセスを表示します。複数のPIDをカンマで区切って指定することもできます。 |
-l |
長いフォーマットで表示します。プロセスに関するより詳細な情報を含みます。 |
--forest |
プロセスを木構造で表示します。プロセスの親子関係がわかりやすくなります。 |
ps
コマンドは非常に多機能で、システムの現在の状態を把握するのに役立ちます。実際の使用例をいくつか紹介します。
全てのプロセスを表示
ps -Aユーザー名、プロセスID、プロセスの状態、コマンド名を含む、全てのプロセスを表示
ps aux文字列に一致するプロセスを検索
ps aux | grep [文字列]完全なコマンド文字列を含む、実行中のすべてのプロセスをリスト表示
ps auxwwプロセスの親 PID を取得
ps -o ppid= -p pidメモリ使用量に基づいてプロセスを並べ替え
ps -mCPU 使用率でプロセスを並べ替え
ps -r特定のユーザーのプロセスを表示
ps -u ユーザー名プロセスID、コマンド名を表示
ps -o pid,commps
コマンドのオプションはシステムによって異なる場合があります。使用するシステムの
man ページや ps --help
コマンドを参照して、使用可能なオプションを確認してください。
kill
kill
コマンドは、指定されたプロセスにシグナルを送信するために使用されます。主にプロセスの終了を目的としていますが、様々なシグナルを送信することで異なるアクションを引き起こすことができます。
killコマンドの基本的な使用法
kill [シグナルオプション] プロセスIDよく使われるオプションとシグナル
| オプション | 説明 |
|---|---|
-l |
利用可能なシグナルのリストを表示します。 |
-s |
送信するシグナルを指定します。シグナル名またはシグナル番号で指定できます。 |
-9 |
強制終了(KILLシグナル)を送信します。最も強力で、ほとんどのプロセスを即座に終了させます。 |
シグナルの例
| シグナル | 名前 | 説明 |
|---|---|---|
| 1 | SIGHUP | プロセスにハングアップを通知します。 |
| 2 | SIGINT | プロセスに中断を通知します(例: Ctrl+C)。 |
| 9 | SIGKILL | プロセスを強制終了させます。終了を拒否することはできません。 |
| 15 | SIGTERM | プロセスに終了を通知します。デフォルトのシグナルです。 |
プロセスID 12345 のプロセスを終了させる(SIGTERM)
kill 12345プロセスID 12345 のプロセスを強制終了させる(SIGKILL)
kill -9 12345利用可能なシグナルのリストを表示
kill -lkill
コマンドは多くのUNIX系OSで標準的に利用されるツールであり、プロセス管理において非常に重要な役割を果たします。正しく使用することで、システムの制御をより柔軟に行うことができます。
tmux
tmuxはターミナルマルチプレクサーであり、複数のターミナルセッションを1つの画面内で管理できるツールです。ターミナルの画面を分割管理できます。この記事では、macOSにtmuxをインストールし、基本的な使い方を解説します。
| OS | インストールコマンド |
|---|---|
| macOS | brew install tmux |
| Raspberry Pi OS | sudo apt update sudo apt install tmux |
tmuxの基本的な使い方
| コマンド | 説明 |
|---|---|
tmux |
新しいtmuxセッションを開始 |
tmux new -s セッション名 |
名前付きで新しいセッションを開始 |
tmux attach -t セッション名 |
既存のセッションにアタッチ |
tmux ls |
実行中のセッション一覧を表示 |
tmux detach |
セッションからデタッチ (tmux内で Ctrl+b その後
d を押す) |
tmux内での基本的な操作
tmuxでは、デフォルトでCtrl+bがプレフィックスキーとして使用され、これを押した後に特定のキーを押すことで様々な操作ができます。
| キー | 説明 |
|---|---|
% |
現在のウィンドウを左右に分割 |
" |
現在のウィンドウを上下に分割 |
c |
新しいウィンドウを作成 |
n |
次のウィンドウに移動 |
p |
前のウィンドウに移動 |
& |
現在のウィンドウを閉じる |
[ |
スクロールモードに入る (終了はqキー) |
これらは基本的な操作ですが、tmuxは非常にカスタマイズ性が高いため、.tmux.confファイルを編集することでキーバインドや挙動を自分好みに設定することが可能です。
画面を上下に分割
ターミナルで$ tmuxを実行後、Ctrl +bを押してから"を押します。下図のように画面が上下に分割されます。

| 説明 | 操作 |
|---|---|
| パネル間を移動する | Ctrl + b を押した後、矢印キーで移動できます。 |
| パネルを閉じる | $ exitを実行してパネルを閉じます。 |
vim
カーソル移動
| 入力 | 動作 |
|---|---|
Ctrl + u |
半画面分上にスクロール |
Ctrl + d |
半画面分下にスクロール |
gg |
ファイルの先頭に移動 |
G |
ファイルの末尾に移動 |
$ |
行の最後へ移動 |
0 (ゼロ) |
行の先頭へ移動 |
^ |
行の最初の非空白文字へ移動 |
w |
次の単語の先頭へ移動 |
b |
前の単語の先頭へ移動 |
} |
次の段落へ移動 |
{ |
前の段落へ移動 |
コマンド
| 入力 | 動作 | 備考 |
|---|---|---|
:w |
ファイルを保存 | |
:q |
Vim を終了 | |
:wq |
保存して終了 | |
ZZ |
変更を保存して終了 | :wq と同等 |
ZQ |
変更を破棄して終了 | :q! と同等 |
編集
| 入力 | 動作 | 備考 |
|---|---|---|
i |
挿入モードへ移行 | |
a |
カーソル位置の後ろから挿入モードへ | |
o |
新しい行を追加して挿入モードへ | 下に新しい行 |
O |
新しい行を追加して挿入モードへ | 上に新しい行 |
x |
カーソル位置の文字を削除 | |
dw |
カーソル位置の単語を削除 | d は削除コマンドのプレフィックス |
dd |
カーソル位置の行を削除 | |
gg + d + G |
内容をすべて削除 | |
yy |
カーソル位置の行をコピー | y はコピーのコマンド |
p |
コピーした内容を貼り付け | |
/検索語 |
文書内での検索 | |
n |
次の検索結果へ移動 | |
N |
前の検索結果へ移動 | |
u |
アンドゥ | 直前の操作を元に戻す |
Ctrl + r |
リドゥ | アンドゥを元に戻す |
sudoを忘れてvim実行後にreadonlyでも保存する
以下のコマンドをvimのコマンドモードで使用します。
:w !sudo tee %このコマンドはどのように機能するかというと、wコマンドはファイルを書き込むためのものですが、!を使用することで外部コマンドを実行できます。sudo tee %は現在のファイル(%が現在のファイル名に展開されます)に対してsudo権限でteeコマンドを実行し、入力をファイルに書き込みます。これにより、読み取り専用で開いてしまったファイルも、sudo権限があれば保存することができます。
成功すると、ファイルはsudo権限で上書き保存されます。ただし、この操作を行うには、sudoを使用する際のパスワード入力が求められる場合があります。また、この方法を使うことでファイルの所有者やパーミッションが変わる可能性があるので注意が必要です。
:w !sudo tee % コマンドは、Vim
で読み込み専用ファイルを開いた後に編集内容を保存したいときに特に便利なコマンドです。このコマンドの動作を理解するために、それぞれの部分を分解してみましょう。
:wコマンドは、現在の編集内容をファイルに書き出します。!は、外部コマンドを実行するためのプレフィックスです。sudoは、スーパーユーザー権限でコマンドを実行するためのコマンドです。teeコマンドは、標準入力から受け取った内容をファイルに書き込みつつ、標準出力にも出力します。%は、Vim で現在編集中のファイル名に展開されます。
つまり、:w !sudo tee % コマンドは、Vim
の現在の編集内容をスーパーユーザー権限で現在編集中のファイルに保存するために使用します。この方法は、ファイルのパーミッションが原因で直接ファイルを保存できない場合に特に便利です。
特定の行へ移動する
Vimで特定の行へ移動するには、コマンドモードで行番号を指定してジャンプするコマンドを使用します。以下の方法で特定の行に直接移動できます。
:<行番号>を入力してEnterキーを押します。たとえば、50行目に移動したい場合は、:50と入力します。- 通常モードで
50Gもしくは50ggを使用しても、50行目にジャンプできます。この場合、50は目的の行番号に置き換えてください。
これらのコマンドを使用すると、大きなファイル内でも素早く特定の位置に移動することができます。
バッファ間の素早い移動
| 入力 | 動作 |
|---|---|
:ls |
開いているバッファのリストを表示 |
:b <番号> |
指定番号のバッファへ移動 |
:bn |
次のバッファへ移動 |
:bp |
前のバッファへ移動 |
:bd |
現在のバッファを閉じる |
:bnext |
次のバッファへ移動(:bn と同じ) |
:bprev |
前のバッファへ移動(:bp と同じ) |
:bfirst |
最初のバッファへ移動 |
:blast |
最後のバッファへ移動 |
:bdelete |
指定のバッファを閉じる(複数可能) |
複数のファイルをバッファとして開いている場合に、これらのコマンドで素早くバッファ間を移動できます。E37:
No write since last change (add ! to override)
エラーが出た場合は、:wで一旦保存したからバッファ移動するとエラーの解消ができます。
バッファとは
Vim での「バッファ」は、開いているファイルの内容をメモリに保持するための領域を指します。ファイルを開くと、Vim はその内容をバッファに読み込み、編集作業はこのバッファ上で行われます。
バッファを活用することで、複数のファイルを同時に開いて作業することができ、効率的にファイル間を移動しながら編集を進めることが可能になります。たとえば、コードを書いているときに参照用のドキュメントを別のバッファで開いておくことができます。また、バッファを使って一時的なメモを取ることもできます。
ファイル内の文字列を一括置換
:%s/検索語/置換後の語/g現在開いているファイル内で検索語を置換後の語で一括置換します。g
フラグはファイル内の全てのインスタンスに対して置換を行います。
セッションの保存と復元
- 保存:
:mksession ~/session.vim - 復元:
vim -S ~/session.vim
Vim の現在のセッション(開いているタブ、ウィンドウ、レイアウトなど)を保存し、後で再開することができます。これは複数のファイルを同時に編集しているときに特に便利です。
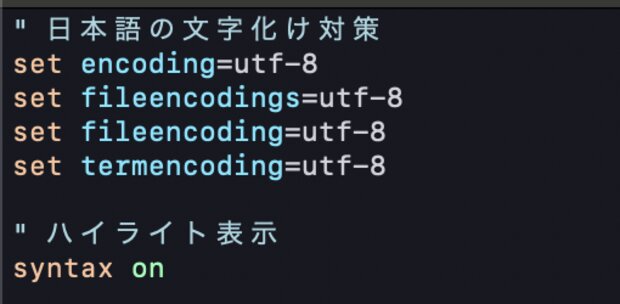
Vimで表示した際にUTF-8の日本語が文字化けする
vi ~/.vimrc で以下を追加します。.vimrc
が存在しなければ、新規で作成しましょう。
" 日本語の文字化け対策
set encoding=utf-8
set fileencodings=utf-8
set fileencoding=utf-8
set termencoding=utf-8.vimrc の記述内でのコメントアウトは
"(ダブルクオーテーション)
ではじまるので、注意しましょう。
ハイライト表示(プログラムとコメントに色をつけたい)
vi ~/.vimrc で以下を追加します。
" ハイライト表示
syntax on▼ こんな感じで色がつきます。
tldr
シェルコマンドの使い方を調べる際にみなさんどうやられてますか?私の場合はネットでググったり、ChatGPTに問い合わせたりしてます。最近だとそれも面倒なので、自分がよく使いそうなコマンド例をこのブログにまとめて、検索できるようにしてます(試しにこのブログでスラッシュを押して、検索ボックスに find と入力してみてください)。
本来はmanのドキュメントで確認するのが一番スマートな気がするのですが、manって読みづらくないですか?オプションの意味を調べるのはまだ良いのですが、逆引きで〇〇を実現させるためのオプションを調べようとするとかなり難しいです。なので私はmanドキュメントが苦手で、あまり使ってません。
Linuxコマンドのポケットリファレンス でも買おうかなと思ったのですが、最近 UNIXという考え方 を読んでいて非常に面白く、まさに「UNIXという考え方」に感銘を受けたのですが、その本では紙媒体を否定されオンライン(manドキュメント)で読むべきだと諭されます(笑)。
どうしたものかと悩んでいたところ、manドキュメントを読みやすく省略して表示してくれるコマンドを発見しました。それがこの記事でご紹介する
tldr です。
ltdr(TL;DR)とは
そもそもtldrは、ネットスラングで使われる(私は使ったことありませんが)TL;DRで、“Too Long, Didn’t Read”のことです。「長すぎて読めませんでした。」という本来の英語の意味から、「要約です。」の意味で使われるそうです。しかし、こちらの記事 に書かれているように、相手を小馬鹿にした意味もあるようですから使う時は気をつけましょう。
さて、 tldr コマンドはGitHubでStarが
47.9k(2024年3月時点)ついている人気のライブラリです。 -
https://github.com/tldr-pages/tldr
tldr を使うと、manドキュメントを要約してくれます。次は
ls コマンドの使い方を表示させた例です。
ltdr lsこのコマンドを実行すると、下図のようにlsコマンドの使い方が要約されて、色付けされた見やすい形で表示してくれます。

これなら、ググったりChatGPTにコマンドの使い方を問い合わせなくても済みそうですね!
tldrのインストール方法
macOSにtldrインストールするには、Homebrewを使用します。
brew install tldrubuntuなどのDebian系Linuxへインストールする場合はこちら。
sudo apt-get install -y tldr基本的な使い方
基本的な使い方は、tldr コマンド名です。例えば、lsコマンドの使用例を見たい場合は以下のように入力します。
tldr ls出力される情報には、簡単な説明、基本的な使用例、オプションの使用例が含まれます。
tldrにはいくつかのオプションがありますが、よく使われるものには以下のようなものがあります。
tldrのデータベースを更新
tldrの内部で管理されているデータベースを最新のものへ更新します。
tldr -u表示可能なコマンドの一覧を表示
tldr -l指定した言語でページを表示
指定した言語でページを表示します。例:
-L jaは日本語で表示します(私の環境では使えませんでした)。
tldr -L ja lstldrは、日常的にコマンドラインを使用するプログラマーやエンジニアにとって、迅速にコマンドの使用例を確認できる非常に便利なツールです。特に新しいコマンドを学ぶ際や、あまり頻繁に使わないコマンドのオプションを思い出したいときに役立ちます。
column
macOSのターミナルでCSVを整形して表示できないかと探していたところ、csvkitやcsvlookのアプリケーションをインストールして実現できるようです。しかしもっと簡単な方法がありました。columnというバンドルされているコマンドを使うことで、CSVを整形して表示させることが可能です。Shift-JISでエンコードされたCSVはそのままだと文字化けしてしまいますが、これはiconvでUTF8へエンコードしてからcolumnへ標準出力して渡してあげればクリアできる問題です。
columnを使ってターミナルでCSVを整形して表示
iconv -f SJIS -t UTF8 test.csv | column -t -s"," | less -#2 -N -Sコマンドを見ていただければ、これ以上の説明はいらないでしょう。ビューワーはお好みのものをお使いください。ここではlessを使用しました。
lessの操作
いちおう、lessの基本操作を記述しておきます。
| 操作 | 実行結果 | 備考 |
|---|---|---|
u or w |
半ページ戻る | |
d |
半ページ進む | |
g |
先頭へ飛ぶ | |
G |
最終行へ飛ぶ | |
n |
検索 | |
F |
ファイルの更新を監視して リアルタイムで反映 |
ctrl+cで終了 |
q |
終了 |
さらに詳しくは $ man less をご覧ください。
シェルスクリプトにして使いやすいようにする
最初に紹介したワンライナーのコマンドを少し改造して、シェルスクリプトにしてみました。
#!/bin/bash
if [[ $# -lt 1 ]]; then
echo "Usage: csv <file>"
exit 1
fi
# nkfを使用してファイルのエンコーディングを判定
encoding=$(nkf --guess "$1" | cut -d " " -f 1)
# 判定されたエンコーディングがUTF-8なら、iconvをスキップ
if [[ $encoding == "UTF-8" ]]; then
cat "$1" | column -t -s","
else
# 判定されたエンコーディングを使用してiconvを実行
iconv -f "$encoding" -t UTF8 "$1" | column -t -s","
fi
ファイルのエンコードを自動検出するために、nkfコマンドを使いますのでない場合はインストールしておきます。
このシェルスクリプトをPATHを通した~/binなどに、ファイル名csvで配置し、実行権限を与えたとします。次のようにして使うことが可能になります。
$ csv <CSVファイル名>実行例
less -#2 -N -S
もalias less='less -SNIK'でaliasに登録しておくと便利です。次のようにしてCSVファイルを表示できます。
csv plants.csv | less
CSVファイルがShift JISだろうが、UTF-8だろうが、自動でエンコードして整形表示されます。めちゃ便利になりました!
テーブルの縦横を転置する
さらにCSVファイルを縦横入れ替えて転置する機能を、先ほどのシェルスクリプトに実装してみました。csv -t <CSVファイル名>で転置モードに切り替わります。
#!/bin/bash
# 転置オプションの初期値を設定
transpose=0
# オプション解析 (-t で転置を行う)
while getopts ":t" opt; do
case ${opt} in
t )
transpose=1
;;
\? )
echo "Invalid option: $OPTARG" 1>&2
;;
esac
done
shift $((OPTIND -1))
if [[ $# -lt 1 ]]; then
echo "Usage: csv <file>"
exit 1
fi
# CSVファイルを転置して整形する関数
transpose_and_format() {
awk -F, '{
for (i=1; i<=NF; i++) a[i,NR]=$i
} END {
for (i=1; i<=NF; i++) {
for (j=1; j<=NR; j++) printf "%s,", a[i,j];
print ""
}
}' | sed 's/,$//' | column -t -s,
}
encoding=$(nkf --guess "$1" | cut -d " " -f 1)
if [[ $transpose -eq 1 ]]; then
if [[ $encoding == "UTF-8" ]]; then
cat "$1" | transpose_and_format
else
iconv -f "$encoding" -t UTF8 "$1" | transpose_and_format
fi
else
if [[ $encoding == "UTF-8" ]]; then
cat "$1" | column -t -s","
else
iconv -f "$encoding" -t UTF8 "$1" | column -t -s","
fi
fi
実行例
$ csv plants.csv | less
を実行してみると下図のように転置されて表示されます。もちろんShift-JISなどのエンコードにも対応しています。
